Flask作为Python语言中最为轻量的Web框架, 由于其核心内容的简洁以及良好的可拓展性, 一直受到广泛的开发者所喜爱。 对比于Django, Flask并没有”我给你的就是最好的, 别管那么多, 拿着用就好”的思想, 而是让开发者自己做出选择, 自己设计开发一个组件, 或者挑选一个你喜欢的第三方库。
1. 标准Web开发流程
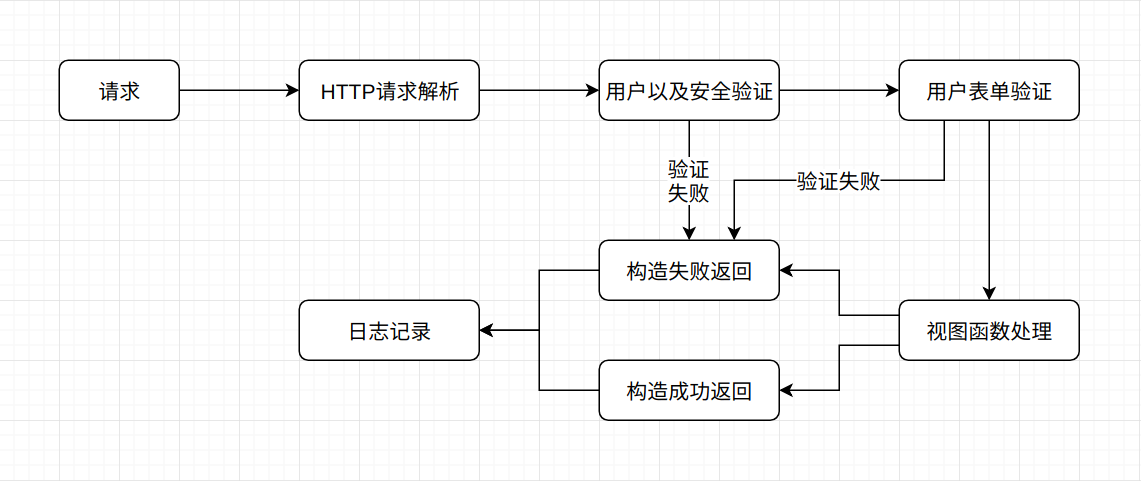
不管开发人员使用什么样的语言, Python也好, Java也好, 又或者什么样的Web框架, 从宏观上来看, 它们的开发流程都是基本相同的。
当服务器收到一个请求时, 首先做的就是对HTTP请求中的参数进行解析, 包括请求的URL, 请求方法, 参数以及Cookie等参数, 将其置于框架的一个内部数据结构中, 便于后续的使用。 在处理完请求参数后, 会在请求正式进入视图函数之前做一些额外处理, 例如验证CSRF-Token, 验证用户Cookie是否合法, 请求的IP是否处于白名单中, 如果验证信息未通过, 则直接返回相应的HTTP状态码以及相关信息, 增强网站的安全性。 在所有的验证通过之后, Web框架根据URL找到对应的视图函数并进行处理, 在处理过程中可能会涉及数据库, Redis以及消息队列的使用, 并很可能存在异步任务的触发。
在视图函数处理过程中, 很有可能因为某些操作而导致异常的产生, 此时Web应用应该判断异常产生的由来, 并进行统一的异常处理。 不管是数据库连接异常, 还是用户表单验证未通过, 都应该给出一个统一的应答, 这样便于前端的数据处理, 也能够让用户知道到底发生了什么。
很多时候为了便于开发人员的错误筛查, 都会在请求返回时添加日志的输出, 包括请求的URL, 请求方法, 参数, 服务器处理该请求的总时间, 请求响应状态码等信息。
2. 一个最简单的Flask Demo
在了解了一般性的标准Web开发流程之后, 接下来就是使用Flask来完整构建这个流程。 项目是由简入繁的, 博客也同样如此。
from flask import Flask
app = Flask(__name__) # ①
app.route("/api/hello") # ②
def hello():
return "Hello World~"
if __name__ == "__main__":
app.run(host="127.0.0.1", port=8080, debug=True) # ③
①: 通过传入当前.py文件的名称构建Flask核心对象, 此时app对象就有了Flask所有的核心功能, 包括添加视图函数, 添加额外的处理函数等。
②: 通过app对象的route方法, 使用语法糖对视图函数进行了装饰, 并传入/api/hello这个URI作为参数。 简单的理解就是当我们请求/api/hello路径时, 请求会使用hello函数作为视图函数进行处理。
③: 运行Flask框架, 并绑定本地127.0.0.1:8080, 以调试模式运行。
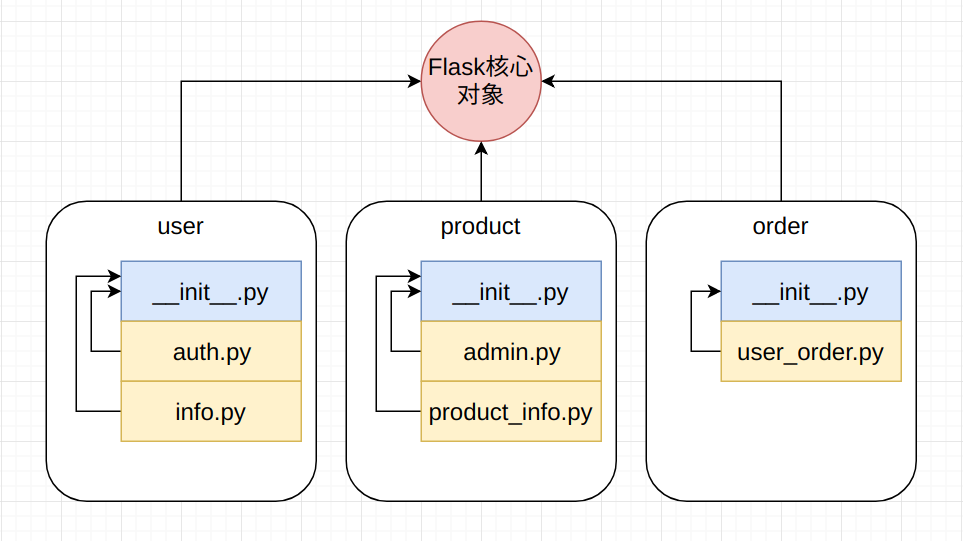
不管是路由注册, 还是以本地运行Flask, 都需要Flask核心对象的参与, 在Demo中也就是app对象。 在大型的Flask应用中, 同样如此, Flask核心对象将会作为中间枢纽, 由各种组件向其进行注册。
3. Blueprint
对于一个中型应用而言, 通常会对各种接口进行业务上的分类。 例如一个商城, 会有user模块, product模块, order模块, coupon模块等等。 除了这些业务需要, 还有一些内部调用的接口, 比如用户分析, 订单分析等。 如果将这些接口都写在同一个文件中, 可以预见的是, 文件长度将会达到上万行。
所以, 不管我们使用什么样的标准来对接口进行分类, 分类都是必须要做的。 在解释Flask蓝图之前, 以Django为例, 这样更加便于理解。
在Django中, 模块的区分是采用app来实现的。 用户Cookie的处理是一个app, 订单是一个app, 商品相关的接口也将组成一个app。 Django在settings.py中提供了INSTALLED_APPS来帮我们自动地管理这些app, 当我们使用django-admin startapp app_name来创建一个app时, 实际上是创建了一个python package, 而在Django中, 正是通过管理python package来完成对app的管理。
我们只需要将package的名称添加至INSTALLED_APPS列表中即可, 剩下的模块查找工作由Django处理。
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
...
'user',
'order',
'product',
'cupon'
]
而在Flask中, 虽然也提供了类似的机制, 但是其实现方式远没有Django这么直观, 相反的, 这也是Flask中比较难以理解的部分。
Blueprint就是Flask中协助我们将接口拆分成不同app的工具, 并由Flask核心对象完成对这些app的收集。 在Flask中, 并不是使用package这一粒度进行管理, 而是单一的py文件。 正是因为粒度从package缩小至了单独的py文件, 所以Blueprint的使用才看起来很复杂。
在有了这一基本的理解之后, 使用Blueprint就非常的简单了。 假如在user模块中, 有两个视图函数文件, 分别命令为auth.py和info.py, 其文件组织如下:
— user
|-- __init__.py
|-- auth.py
|-- info.py
在auth.py以及info.py中均包含了一些视图函数, 由于我们对接口进行的功能拆分, 所以此时Flask核心对象就需要由Blueprint对象代替:
# auth.py
from flask import Blueprint
bp = Blueprint("auth", __name__, url_prefix="/api/auth")
bp.route("/login", methods=["POST"])
def login():
...
bp.route("/logout", methods=["GET"])
def logout():
...
同样地, 对info.py如法炮制:
# info.py
from flask import Blueprint
bp = Blueprint("info", __name__, url_prefix="/api/info")
bp.route("/nick_name", methods=["GET"])
def get_nick_name():
...
现在对user.py和info.py进行了Blueprint方式地重写, 那么如何将其与Flask核心对象产生挂接? 答案是在user模块的__init__.py中对其进行注册:
# user.__init__.py
from . import auth, info
def register_user(app):
app.register_blueprint(auth.bp)
app.register_blueprint(info.bp)
此后, 只需要在创建Flask核心对象的文件中将register_user函数导入, 并传入核心对象进行调用即可。
# app.py
from flask import Flask
from myFlaskDemo.user import register_user
app = Flask(__name__)
register_user(app)
无论有多少个app, 都可以通过这样的方式将其注册进Flask核心对象之中, 只不过因为Blueprint是对单一的py文件进行管理的, 所以就需要比Django做更多的工作来完成这件事情, 其本质上, 都是让Flask核心对象发现这些视图函数而已。
4. 请求的参数处理
在使用POST方法进行请求时, 通常是使用JSON的方式进行参数传递, 那么如果我们想要取出相应的数据的话, 就势必需要对JSON数据进行json.loads操作, 转换成Python字典。 这个过程每个处理POST请求的视图函数都需要进行, 非常的麻烦, 所以我们需要想办法在请求进入视图函数之前就将数据保存在某一个地方。
这个时候就需要用到before_request这个函数, 同样是由Flask核心对象所提供。 before_request接收一个函数, 并在每次请求到达视图函数之前执行它。
from flask import Flask, request
from werkzeug.datastructures import ImmutableMultiDict, CombinedMultiDict
app = Flask(__name__)
def get_request_params_from_json():
json_data = None
data = request.get_json(silent=True)
if isinstance(data, dict):
json_data = ImmutableMultiDict(json_data)
request.params = CombinedMultiDict(filter(None, [json_data, request.form, request.args]))
app.before_request(get_request_params_from_json)
5. 约定返回格式
数据返回格式的统一与否是检验一个Web API是否合格的最低标准, 这是一个对前端, 自己以及同事都有利的东西, 所以目前已经成为了一种标准。
就目前来说, 用的最多的格式就是code, message, data, 即:
{
"code": 成功码 or 错误码,
"message": 错误信息 or '',
"data": ...
}
以RESTful API而言, 通过HTTP响应的状态码来判断当前访问的结果, 但是呢, 部分的前端程序员对此非常不感冒, 觉得处理HTTP-code相当麻烦。 所有的请求, 不管是表单验证我失败, 还是用户未登录而访问受保护的资源, 这些情况统统给我返回200, 然后在message字段中标明原因。
很多时候系统出现的问题, 真的就不是技术问题, 而是眼界问题。 通常我们需要定义两个函数, success以及fail函数, 接收code, message, data参数, 调用方根据情况进行参数传递即可:
def success(data):
resp = {'code': 200, 'message': '', 'data': data}
data = json.dumps(resp)
return Response(data, status=http_code, mimetype='application/json'})
def fail(code, message, data):
resp = {'code': code, 'message': message, 'data': data}
6. 请求日志的记录
这部分内容是我认为最有价值的一小节, 无数个被产品打断的瞬间, 告知某个用户的某次操作异常, 而又没有准确日志的记录, 无从排查的教训。 所以在写这部分内容时, 坐在轮椅上的我格外激动…
血一样的教训告诉我, 日志记录一定要全面, 谁请求了哪个URL, 请求方法是什么, 请求参数是什么, 请求响应时间多多少, 这些通通都要记录, 少一个都不行。
下面给出一个示例:
def record_request_log(response, *args, **kwargs):
now_time = time.time()
request_start_time = getattr(request, 'request_start_time', None)
user_id = getattr(request, 'user_id', None)
format_str = (
'%(remote_addr)s request: [%(status)s] %(method)s, url: %(url)s, '
'args: %(args)s, json: %(json)s, '
'request_start_time: %(request_start_time)s, response_time: %(response_time)s, '
'user_id: %(user_id)s, '
)
data = dict(
remote_addr=request.remote_addr,
status=response.status,
method=request.method,
url=request.url,
args=request.args,
json=request.get_json(silent=True),
request_start_time=str(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())),
response_time = now_time - request_start_time if request_start_time is not None else ""
user_id=user_id,
)
logger = logging.getLogger('response')
logger.info(format_str, data)
return response
app.after_request(record_request_log)
同时, 为了让日志的记录更加完整, 例如ERROR日志记录到文件, 或者是通过Kafka发送给ELK日志分析平台, 所以需要对日志的格式进行额外的配置:
# log_config.py
DEFAULT_LOGGING_CONFIGS = {
'version': 1,
'disable_existing_loggers': True,
'formatters': {
'standard': {
'format': '%(asctime)s [%(threadName)s] [%(name)s:%(funcName)s] '
'[line:%(lineno)d] [%(levelname)s]- %(message)s'}
},
'handlers': {
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler',
'filename': os.path.join(BASE_DIR, 'log', 'error.log'),
'maxBytes': 1024*1024*5,
'backupCount': 5,
'formatter': 'standard',
},
'console':{
'level': 'INFO',
'class': 'logging.StreamHandler',
'formatter': 'standard'
},
},
'loggers': {
'root': {
'handlers': ['error', 'console'],
'level': 'INFO',
'propagate': False
},
'response': {
'handlers': ['error', 'console'],
'level': 'INFO',
'propagate': False
}
}
}
# app.py
import logging
import logging.config
def create_app():
...
init_log()
return app
def init_log():
logging.config.dictConfig(DEFAULT_LOGGING_CONFIGS)
7. Flask中的应用上下文与请求上下文
在AppContext以及RequestContext中, 使用最多的仍然是RequestContext, 意思为请求上下文。 那么请求上下文是个什么东西?
在SpringBoot以及Django框架中, request对象是通过函数参数进行传递的, 比如在Django中, 通常会有这样的代码:
class SomeUsefulAPIView(APIView):
def post(self, request);
data = request.data
...
然而在Flask中, 却不是这样的:
from flask_restful import Resource
from flask import request
class SomeUsefulAPIView(Resource):
def post(self):
print(request.data)
request对象是通过import进行导入的, 而不是通过参数进行传递的, 这里其实就是请求上下文的表现形式。 在当前的请求线程中, Flask会保存request对象, 并能够在任意文件中通过导入的方式进行使用, 其底层依赖于werkzeug第三方库的LocalStack。
更进一步地, LocalStack封装底层的Local实现, 而Local对象, 其实就是一个大字典。 首先来看现象:
import time
import threading
from werkzeug.local import Local
foo = Local()
foo.bar = 15
def another_threading():
# 开启线程对foo对象的属性进行修改
foo.bar = 20
time.sleep(3) # 确保主线程打印出变量
print("another_thread: {}".format(foo.bar))
if __name__ == "__main__":
t = threading.Thread(target=another_threading, args=())
t.start()
time.sleep(1) # 确保t线程执行完毕
# 打印主线程变量值
print("main thread: {}".format(foo.bar)) # 15
foo.bar = 25
可以看到, 在主线程中, foo.bar的值并没有受到另外一个线程的影响, 而在t线程中, 也没有受到主线程的影响, 这就是Local对象的作用: 同一个对象, 在不同的线程中拥有完全独立自主权, 并且其值不会受到其它线程的影响。
现在来看Local类的源码, 主要是使用Python类字典的功能, 重写__getattr__以及__setattr__方法:
class Local(object):
__slots__ = ("__storage__", "__ident_func__")
def __init__(self):
object.__setattr__(self, "__storage__", {}) # 初始化__storage__变量为字典结构
object.__setattr__(self, "__ident_func__", get_ident)
# get_ident为Python内置的函数, 其作用为获取当前线程的线程id
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name]
except KeyError:
raise AttributeError(name)
def __setattr__(self, name, value):
ident = self.__ident_func__() # 函数调用, 获取id值
storage = self.__storage__ # storage其实就是一个dict
try:
# 适用于 {"140672512972544": {"bar": "25"}}的结构
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
所以说, 在上面的测试代码中, storage变量的内容为:
{
"线程id-1": {
"foo": 25
},
"线程id-2": {
"foo": 20
}
}
那么LocalStack就很好理解了, 这是一个先进后出的栈结构, 并且栈内容在不同的线程中也是不同的。

如上图所示, 每一个请求在进入时, 都会将request对象压入当前线程的栈中, 那么在该请求的生命周期内, 任意地方都可以将该对象从栈中获取, 并且保证在当前线程中, request请求对象不会被其它线程对象所污染。
所以, 基于此特性, Flask只能使用多线程+协程的方式进行部署, 而不能使用以epoll为底层实现的Reactor模型部署。 所以从这方面来讲的话, 使用Flask解决C10K的问题几乎不能实现。
8. Flask AOP的使用
经常听到别人搞Java的说SpringBoot的AOP多么多么NB, 多么多么厉害, 然而写Python的却是微微一笑, 这东西我们都用烂了。
AOP, 全称Aspect Oriented Programming, 面向切面编程, 在Python中, 装饰器就是一个最佳的面向切面编程的实现。 面向切面编程的含义就是抽离相似逻辑, 将相似的逻辑进行封装并复用, 说白了, 其实就是函数的调用:
def aspect_function(f):
print("在f函数调用之前要做的事情")
try:
result = f() # 调用函数
print("在f函数调用之后要做的事情")
except Exception as e:
print("调用f函数时出现异常时的处理逻辑")
aspect_function函数接收一个函数对象, 并且在其调用之前, 调用之后以及调用出现异常时均作出相同的操作, 那么这些内容其实就是一个切面, 一个所有f函数调用之前, 之后都需要做的事情。
上面的例子稍加改动, 就是一个装饰器, 可以通过语法糖的形式来实现复用。 不管是在Django的全局异常处理, 还是在Flask中, 模型都是这样的。
AOP在Web框架中最常见的场景就是全局异常处理。 在视图函数中, 经常会有一些意想不到的异常抛出, 如果直接返回给用户500的话会很不友好, 所以尽量的将异常使用日志的方式记录下来, 并且返回给用户可读的内容。 而针对每一个视图函数都写一个大大的try..except太累了, 此时就有了errorhandler函数。
def setup_error_handler(app):
@app.errorhandler(Exception)
def error_exception(e):
print("Wrong")
return "Some wrong happened"
setup_error_handler(app)
一个最简单的全局异常处理就此诞生, 并且由于我们传入了所有异常的爹, 即Exception类, 所以所有的Python异常都能够捕捉, 再结合前面的统一返回格式, 初步的全局异常处理就成型了。
9. Flask-migrate的使用
在日常的业务开发中, 数据库的模型不可能一成不变, 总会有新的需求导致数据模型的更改。 而在有ORM模型的Web框架中, 数据库的模型是应该随着应用层的模型代码而变动的。 也就是说, 当我们想要添加/删除某一个字段时, 不能直接在数据库中进行alter table操作, 而是修改应用层代码, 而后通过某种方式将这些改变映射到数据库中。
在Django中, 提供了内置的python manage.py makemigrations/migrate帮助我们完成这件事, 而在Flask中, 需要使用第三方库flask-migrate以及flask-scrip。
首先来定义一个简单的模型:
class TimeMixin(object):
created = Column(DateTime(), default=datetime.now)
updated = Column(DateTime(), default=datetime.now, onupdate=datetime.now, nullable=False)
deleted = Column(Boolean(), default=False, nullable=False)
class User(db.Model, TimeMixin):
id = Column(Integer, primary_key=True, autoincrement=True)
nickname = Column(String(24), nullable=False)
phone_number = Column(String(11), unique=True)
email = Column(String(50), unique=True, nullable=False)
当然, 在首次部署项目时, 可以在代码中直接使用db.create_all(app)的方式来完成数据模型的写入, 但是这种方式过于僵硬, 无法回滚, 也无法添加新的字段。
pip install flask-sqlalchemy
pip install flask-migrate
pip install flask-script
创建manage.py文件, 并写入以下内容:
from flask_script import Manager
from flask_migrate import Migrate, MigrateCommand
from app import create_app, db
migrate = Migrate(app, db)
manager = Manager(app)
manager.add_command('db', MigrateCommand)
if __name__ == '__main__':
manager.run()
- 初始化migrations package:
python manage.py db init
- 创建migration文件(相当于Django中的makemigrations)
python manage.py db migrate -m "initial migrate"
- 将migration文件映射至数据库中(相当于Django中的migrate)
python manage.py db upgrade
此后对模型的修改, 只需要执行python manage.py db migrate -m "Some useful message"以及python manage.py db upgrade即可。
10. 小结
其实Web开发讲究的就是一个套路, 当把一个Web框架理解清楚了之后, 其余的都大同小异, 当然这里指的是同步类Web框架, 诸如Tornado, Netty则不属于此列, 它们由于底层机制的不同, 要更为复杂一些。
有时候看待Web框架也需要使用AOP的思想, 抽离相似的逻辑, 并用此逻辑去学习各种各样的框架, 这种方式在我看来比首先深入了解细节要更加高效, 因为实现细节必定有所差异, 而本质原理却基本类似。