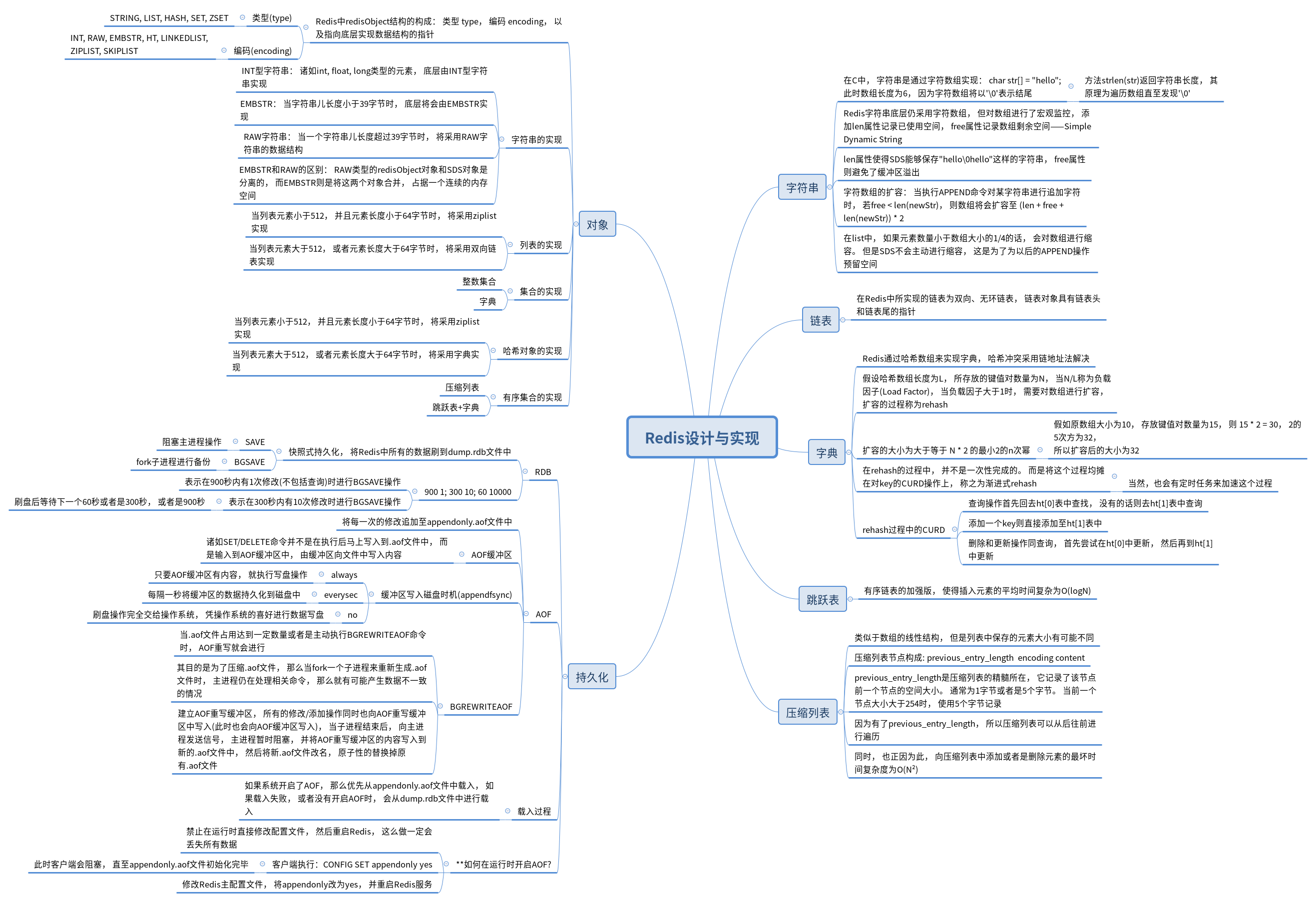
Redis内置了5种对外开放的数据结构, 分别是字符串, 列表, 集合, 有序集合以及哈希对象。 每一种数据结构的底层实现都会由存入的数据产生动态变化, 这也是Redis具有极佳吞吐量的原因之一。 本篇文章主要描述其基本数据结构的实现以及这些结构在使用时的注意事项。
1. String
Sting对象是Redis中使用最为广泛的数据结构, 不管是存储的Key, 还是Value, 都绕不开String对象。
Redis并没有直接使用C语言中传统的字符数组来实现字符串, 而是对其进行了一层包装, 称为简单动态字符串(Simple Dynamic String, SDS)。
首先对C语言中的字符串进行一个简单的介绍, 毕竟没有对比就没有伤害。 C语言是使用一个以\0结尾的字符数组来表示字符串的。 当我们想要判断一个字符串的长度时, C会对数组进行遍历, 直到发现\0标识为止。
int main() {
char data[] = "hello";
printf("%d", strlen(data)); // 输出为5
printf("%d", sizeof(data)); // 输出为6
}
之所以sizeof函数对数组调用的结果为6, 是因为在数组末尾保存了\0, 即null这个标识位。 那么问题就来了, 如果我们有一个字符串是hello\0hello的话, C语言只会把它当作是hello字符串对待。
基于这个问题, SDS结构对字符数组的使用长度, 以及空闲长度进行了记录, 避免此类问题的发生:
struct sdshdr {
int len;
int free;
char buf[];
}
这样一来首先能够在O(1)的时间内获取字符串长度, 而C字符串则需要O(N)的时间复杂度。 并且在字符串拼接时, 能够避免缓冲区溢出问题。
2. 字符串对象以及常用命令
字符串对象的编码可以是int, embstr或者是raw, 这里的字符串对象和SDS有着本质的不同。 SDS是Redis底层的一种字符串实现方式, 而字符串对象则是用户在实际使用过程中产生的对象, 可以理解为SDS是字符串对象的一种组成方式。
在使用set age 1的命令之后, 由于age的值为整型, 没有必要保存成为一个字符串, 所以在Redis内部直接使用整型来进行保存。
对于小于39个字符的字符串对象, Redis采用一次分配内存的方式, 将其保存为embstr类型的字符串对象。 如果字符串字符数量大于39, 则采用两次分配内存的方式, 将其保存为raw类型的字符串对象。 数据的长度是Redis对数据结构优化的唯一指标。
2.1 字符串常用命令
- 设置值
set key value [ex seconds] [px milliseconds] [nx|xx]
ex和px代表了两种时间单位的过期时间, 前者表示秒级过期时间, 后者则代表毫秒级过期时间。
nx和xx是一个非常重要的选项。 nx表示当前键必须不存在才能够设置成功, 用于添加。 xx则相反, 键必须存在才能够设置成功, 用于修改。 nx常常会被作为一种简易的分布式锁来对系统中各进程进行资源的约束。 因为Redis是一个单线程命令处理的系统, 所以如果有多个客户端同时执行setnx命令的话, 只有一个客户端会成功。
- 计数
set access_number 0
incr access_number
同样是利用Redis单线程处理命令的机制, 可以以并发安全的来对某些key进行自增操作, 常用于访问量计数的基础组件。
3. 列表
列表的内部编码有2种, ziplist(压缩列表)和linkedlist(链表), 当列表的元素个数小于512, 或者是列表元素的值都小于64字节时, 会使用ziplist作为内部编码, 否则使用linkedlist。
ziplist主要是为了节省内存而开发的, 其内部实现可参考《Redis设计与实现》。 由于我们对列表结构的索引功能使用并不会很频繁, 添加和移除元素的操作要更多一些, 那么在这种场景下, 链表要比压缩列表更为高效。
3.1 列表常用命令
- 添加元素
lpush|rpush user_list
lpush表示从左侧添加元素, rpush则是从右侧添加元素。
- 删除元素
rpop和lpop分别表示从右侧和左侧删除一个元素, 在客户端操作的比较多。 更为重要的是阻塞操作brpop以及blpop。 brpop表示阻塞的删除列表元素, 当列表为空时, 该命令将会被阻塞。 lpush+brpop是非常常用的组成消息队列的两个命令。
4. 哈希对象
哈希对象的内部编码同样有两个, 压缩列表以及字典。 字典的实现与Python相同, 由哈希数组实现, 并且哈希冲突采用拉链法解决。
这里想要提及的是字典对象的Rehash操作。 如果哈希数组的大小为512, 并且此时保存了1024个节点的话, 那么该哈希表的负载因子为:
load_factor = 1024 / 512 = 2
也就是说, 平均每个数组空间都保存了2个节点元素, 如果哈希算法比较糟糕的话, 很有可能出现下图的情况:

此时的查询效率将会由O(1)转变为O(n), 所以必须要对哈希数组进行扩容, 并对其中的节点进行Rehash操作。 那么问题来了, 该字典外部还在使用, 怎么做到安全, 稳定的Rehash操作呢?
Redis在字典结构中保存了两个数组, 记为ht[0]以及ht[1], 其中ht[1]是专门为了Rehash而生的。
当Redis要对某个字典进行扩容Redis操作时, 首先为ht[1]数组分配足够的空间, 而后每次对字典的删改查的操作, 都会将ht[0]里面的元素重新rehash到ht[1], 而添加操作则直接添加至ht[1]。 也就是说, 在rehash未完成之前, ht[1]保存了ht[0]的部分元素。 随着时间的推移, ht[0]里面的所有元素都被访问时, ht[1]也就有了全部的数据, rehash操作结束。
当然, 有时候字典里面的键可能很久不会被使用, 这样以来该键就不会被rehash到ht[1]数组中, 所以此时可以有一个外部的定时脚本来协助完成这个工作。
Redis通过渐进式Rehash, 多分数据冗余加上外部脚本的方式来完成字典数据的并发扩容。
5. 过期键删除策略
setex可以使得某一个键在未来的某个时间上过期, 从而被Redis删除, 那么Redis是如何实现这个功能的呢?
通常来讲, 过期键删除策略有3种:
- 定时删除: 为每一个键创建一个定时器, 让定时器在键的过期时间将要来临时 , 立即执行对键的删除操作。
- 惰性删除: 对于过期键不做任何处理, 而是再下一次获取该键时检查其过期时间。 如果键过期了再删除。
- 定时脚本: 定时脚本对数据库中所有的键进行定时扫描, 发现过期的键则直接删除。
为每一个键创建定时器的代价太大, 极为浪费服务器资源。 所以Redis采用的是惰性删除+定时脚本的方式来实现过期键的删除策略。
在开发中许多地方都会用到过期这个功能, 例如电商订单45分钟内未支付则返回库存, 并将订单状态改为失效。 惰性删除+定时脚本的方案同样适于这些常规功能的开发。
6. AOF重写缓冲区
AOF文件类似于MySQL的binlog, 将所有数据的修改, 添加以及删除操作均写入appendonly.aof文件中, 其目的就是将内存数据持久化至磁盘, 便于数据在灾难时的恢复。
将内存中持续产生的数据写入磁盘中有很多种方式, 比较常见的就是建立内存缓冲区, 每隔一段时间调用系统的fsync函数将数据一起写入磁盘中。 当然也可以每产生一个数据就写入磁盘, 但是这种方式效率比较低。 Redis所默认的刷盘方式是每秒将AOF缓冲区内的内容写入磁盘中。

如果对列表对象执行了4次操作, 每次均添加一个元素:
lpush name_list "bob"
lpush name_list "qob"
lpush name_list "wob"
lpush name_list "rob"
此时aof文件中将会产生4条记录。 随着时间的推移, aof文件将会变得越来越大, 此时就必须要对aof文件进行重写。 重写的方法也很直白, 像上面的4条命令, 完全可以使用一条命令完成:
lpush name_list "bob" "qob" "wob" "rob"
aof文件重写时也会和字典的扩容产生同样的问题: Redis仍然需要提供服务, 数据的修改不可能停止, 而aof文件重写也必须要进行, 这样一来就会导致数据不一致问题。
字典的扩容采取了一个冗余的扩容数组, 采用渐进式rehash的方式进行数据迁移。 那么在这里, 同样可以对数据进行冗余: 当重写开始时, 建立AOF重写缓冲区, 此时数据记录将会写入AOF缓冲区以及AOF重写缓冲区中。

7. 小结