树型结构由于其良好的递归特性, 高效的查询效率, 在软件系统设计中有着非常广泛的使用。 IO多路复用的epoll实现采用红黑树组织和管理sockfd, 以支持快速的增删改查; Golang中的Timer采用多叉堆实现; Java中的TreeMap以及TreeSet同样采用红黑树实现…而在MySQL中, 索引的构建同样采用树结构实现。
1. 什么是B-Tree
B-Tree简单的来讲就是一颗矮胖的多叉平衡树, 通常不会超过3层。
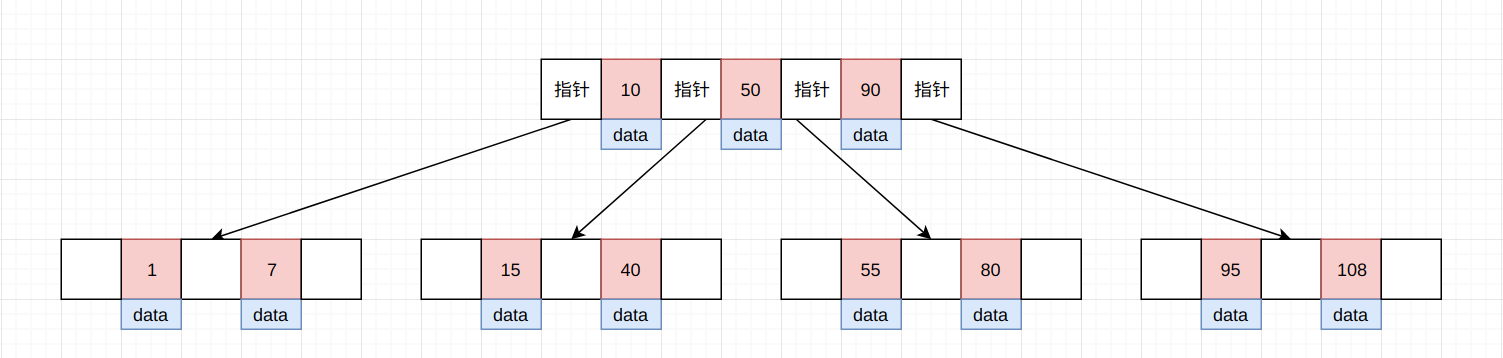
如上图所示, 每一层均由指针, 索引值以及卫星数据组成。 进行搜索时, 同样采用二分查找的方式进行搜索, 所以搜索效率与树的高度直接相关, 这也是为什么B-Tree的树高非常少的原因, 其目的就在于提高搜索效率。
那么既然降低树高能够提高搜索效率, 为什么不干脆使用有序列表呢?
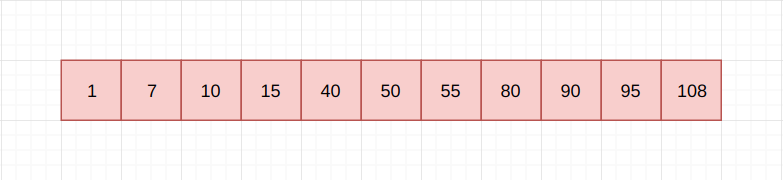
现在树高只有1, 搜索的平均时间复杂度即为O(logn), 不是比B-Tree更快吗? 有一个很关键的点就是, B-Tree是为了构建存储数据的索引而生, 数据量庞大且将会被持久化至磁盘或者SSD上。 如果说某一张表拥有过亿的数据量, 且服务器只有4G的内存, 根本无法将列表形式的索引完全载入内存, 二分查找也就无从说起。
2. 为硬盘存储而生的B-Tree
已经9102年了, 服务器使用HDD作为持久层已经成为了一个过去式, 目前均采用SSD, 即固态硬盘作为持久层, 其读写效率约为HDD的10倍左右。
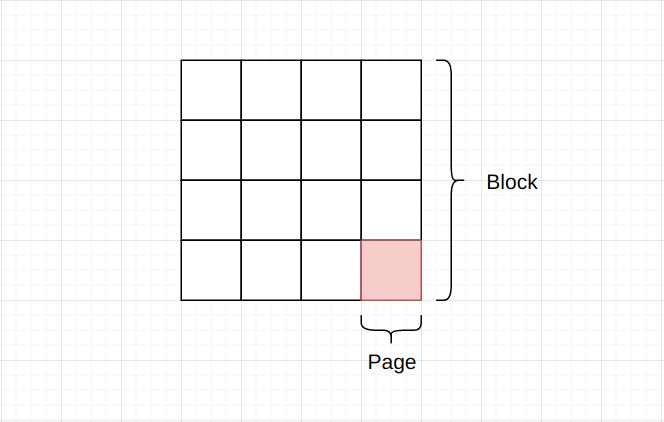
SSD简单的来看是由很多个Block(块)组成, 而Block又由很多个Page(页)所组成。 Page的大小通常为4K或者是8K, Blcok的大小通常为512K。
由于SSD没有向磁盘一样的悬臂, 所以不需要磁头的机械运动, 在读取数据时, 只需要找到数据所在的Block即可。 由于SSD特殊的组成方式, 在进行数据读取时, 其最小单位为Page, 也就是一次最小读取为4K或者是8K。 而对于删除数据来说, 其最小单位为Block, 因为需要进行加压擦除。
B-Tree之所以适合作为数据库索引结构的存储, 就是因为其矮胖的树型结构。 如果我们将索引树改为红黑树或者是AVL树这种二叉树的话, 会发生什么?
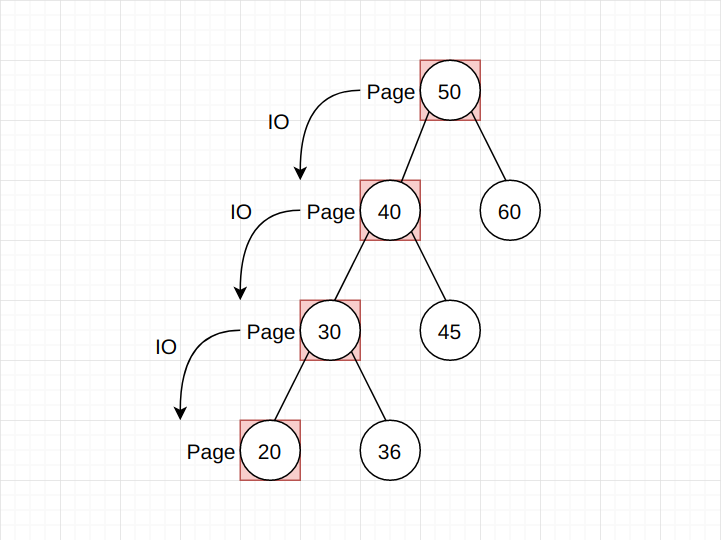
假设树高为4, 所需的数据刚好位于AVL树的叶子节点, 那么在最坏的情况下(数据分散在不同的Page中), 想要取出这条数据, 就需要4次的IO操作。 而IO操作, 相较于CPU的计算, 可以说慢如龟爬。 随着层高的增加, IO次数随线性增长, 这是我们不能接受的。
而对于B-Tree来讲, 就不会存在这样的问题, 因为其树高也就只有3、4层, 无论数据位于叶子节点还是非叶子节点, 其IO次数最多也只是4次而已。
3. B+Tree
B+Tree是B-Tree的进化版, 目的在于进一步减少磁盘IO次数, 提供稳定的查询效率以及优化范围查找。
首先来看B+Tree的基本结构, 与B-Tree最大的不同就是: B+Tree的所有数据均保存在叶子节点, 非叶子节点只保存指针以及索引值。
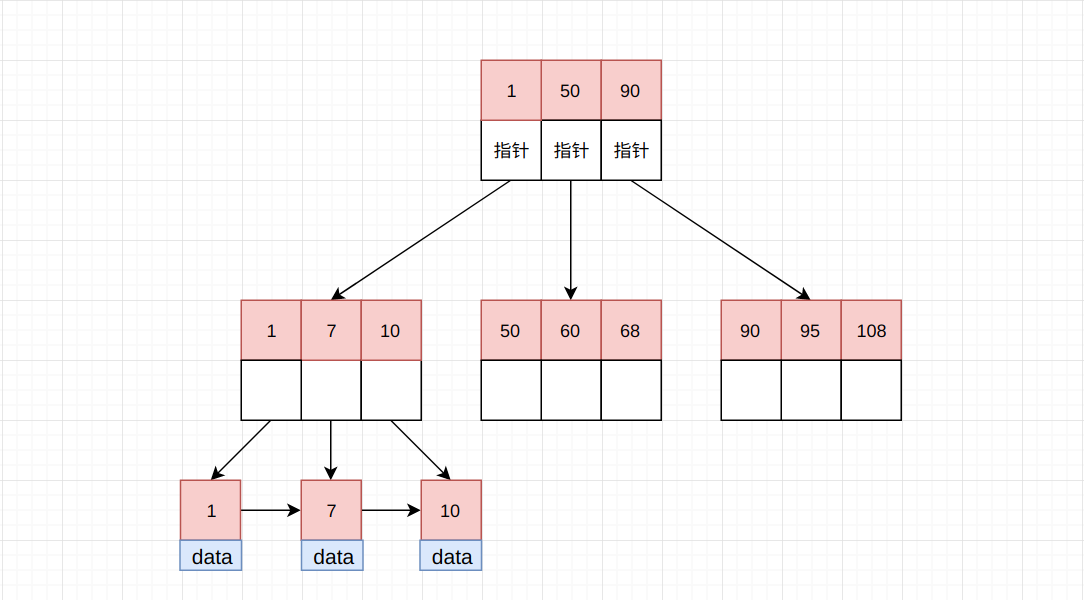
如上图所示, 所有的数据均保存在B+Tree的叶子节点, 非叶子节点不保存数据, 这样一来使得在4K/Page的容量限制下, 能够保存更多的索引数量。 运气好的话原来使用B-Tree需要4层树高, 使用B+Tree的话可能只需要3层树高, 磁盘IO次数进一步降低了。
并且由于B+Tree只在叶子节点保存数据, 所以每一次查询都需要遍历至树底, 而所有叶子节点均处于同一层, 所以所有的查询时间复杂度都是相同的。
除此之外, 在叶子节点所有的数据均使用指针进行相连接, 也就是一个有序链表, 在进行范围查找时拥有极高的效率。 并不需要像B-Tree一样进行前序或者后序遍历。
4. 哈希索引
其实到这里有关B-Tree和B+Tree的内容就结束了, 但是还是忍不住再BB两句。
Hash Table是一种以空间换时间的数据结构, 底层由数组实现, 其平均查询时间复杂度为O(1)。 而B+Tree的平均查询时间复杂度为O(logn), 那么索引为什么不使用哈希表, 而要使用B+Tree呢?
因为在数据库查询这一场景, 取出单一的一条数据这种需求占比并不会特别大, 更多的是使用某一种规则取出符合该规则的多条数据。 如果只是单一的一条数据, 那么哈希索引的效率确实要优于B+Tree。 但如果取出多条数据, 或者对数据进行排序的话, 那么B+Tree为更好的选择。
MySQL的InnoDB存储引擎只允许用户定义B+Tree索引, 不允许用户定义哈希索引, 就是因为无法判断用户是否能正确使用哈希索引。 但是InnoDB会根据实际情况自动地为某些数据添加哈希索引, 以增加查询速度。
5. 小结
从B-Tree以及B+Tree的使用场景上来看, 没有适用于一切场景的数据结构, 只有最适合某些场景的数据结构。 在学习数据结构的过程中, 有时候不仅要关注它的原理, 更需要关注它的设计初衷以及适用场景。