在 PostgreSQL 的旧版本中,常常需要处理大量以指针传值的查询,因而存在着内存泄露的问题,直到查询结束时才能将内存收回。尤其是在处理 TOAST 数据时,需要使用大量的内存,因而使得内存泄露的问题更加明显。为此,PostgreSQL 在 7.1 版本开始实现了内存上下文管理机制。
1. 概述
内存上下文机制本质上就是对内存进行分类和分层。
比如说我们需要为用户发来的命令,例如 "select * from t",开辟一个内存空间并存储它,同时在对命令进行语法解析后生成的语法解析树也需要内存保存,因此 PostgreSQL 使用 MessageContext 来存储。
对于不经常改变的 Catalog Relation 可以放入缓存中,不必每次都从磁盘中读取,那么 Cache 所需的内存就可以由 CacheMemoryContext 进行管理。
当执行一个事务时,一定会伴随着内存分配,比如元组的扫描、索引的扫描或者元组的排序等等,这些内存可能需要在事务结束后才释放,因此可由 CurTransactionContext、ExecutorState、PortalHeapMemory 等内存上下文来管理。
可以看到,在数据库运行过程中,会不断地申请各种各样的内存,PostgreSQL 将其分门别类整理好,在内存释放时就将更加从容和方便。即系统中的内存分配操作在各种语义的内存上下文中进行,所有在内存上下文中分配的内存空间都通过内存上下文进行记录。因此可以很轻松地通过释放内存上下文来释放其中所有的内存,而不用费心地去释放其中的每一块内存。
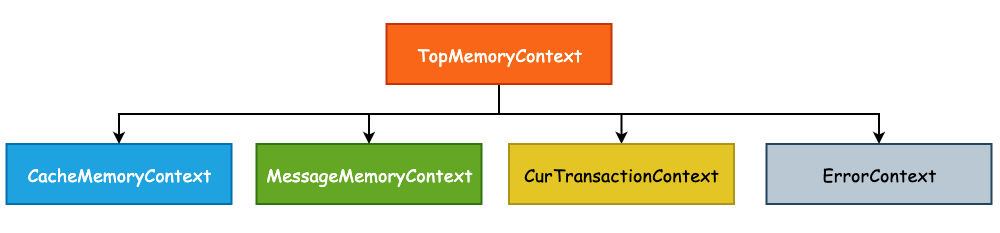
PostgreSQL 中的每一个子进程都拥有多个私有的内存上下文,这些上下文将会组成一个树形结构,更准确地说,是一棵多叉树,根节点为 TopMemoryContext。因为对于数据库而言,一个查询处理是一个层层递进的过程,正如查询计划树一样。下图展示了最常用的几种内存上下文,ErrorContext 专门用于错误处理,因为我们的 Error Message 也需要保存在堆内存上,而后输出至文件中:
2. MemoryContextData
MemoryContextData 是一个抽象类,包含了内存上下文之间的关联关系,以及对内存上下文进行操作的一系列函数,可以有多种实现,但目前只有 AllocSetContext 这一种实现。而在 C 语言中要想实现继承和多态,那么 AllocSetContext 的起始位置就必须是 MemoryContextData,这一点接下来我们就会看到。
首先来看看 MemoryContextData 的具体内容:
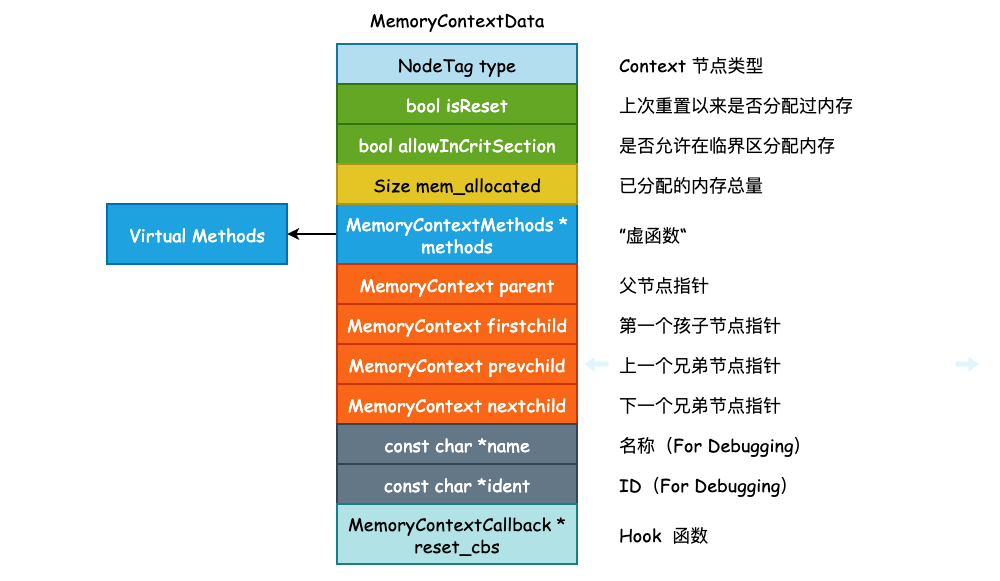
有几个字段需要进一步地解释和说明:
isReset: 表示当前内存上下文从上一次重置到当前是否还没有内存分配,初始值为 true,即重置以来还没有进行内存分配。当进行了内存分配时,该值将会被更新为 false。那么最终在重置内存上下文时,如果发现该字段为 true,则表示该内存上下文还没有进行过内存分配,就可以不进行实际的重置工作,从而提高效率。
methods: 包含了子类必须实现的全部方法,包括内存分配、内存释放等:
typedef struct MemoryContextMethods
{
void *(*alloc) (MemoryContext context, Size size); // 内存分配
void (*free_p) (MemoryContext context, void *pointer); // 内存释放
void *(*realloc) (MemoryContext context, void *pointer, Size size); // 内存重分配
void (*reset) (MemoryContext context); // 内存重置
void (*delete_context) (MemoryContext context); // 删除某个内存上下文
Size (*get_chunk_space) (MemoryContext context, void *pointer); // 获取内存片大小
bool (*is_empty) (MemoryContext context); // 判断内存上下文是否为空
void (*stats) (MemoryContext context,
MemoryStatsPrintFunc printfunc, void *passthru,
MemoryContextCounters *totals, bool print_to_stderr);
} MemoryContextMethods;
前面已经提到了 MemoryContextData 目前只有 AllocSetContext 这一种实现方式,那么这些方法的实现就可以直接在 src/backend/utils/mmgr/aset.c 找到。
parent、firstchild、prevchild 和 nextchild 构成了内存上下文的树形结构,并且每一个节点都保存了其父指针和兄弟指针,也就是说,只要能拿到树中的任意一个节点即可对整棵树进行遍历:
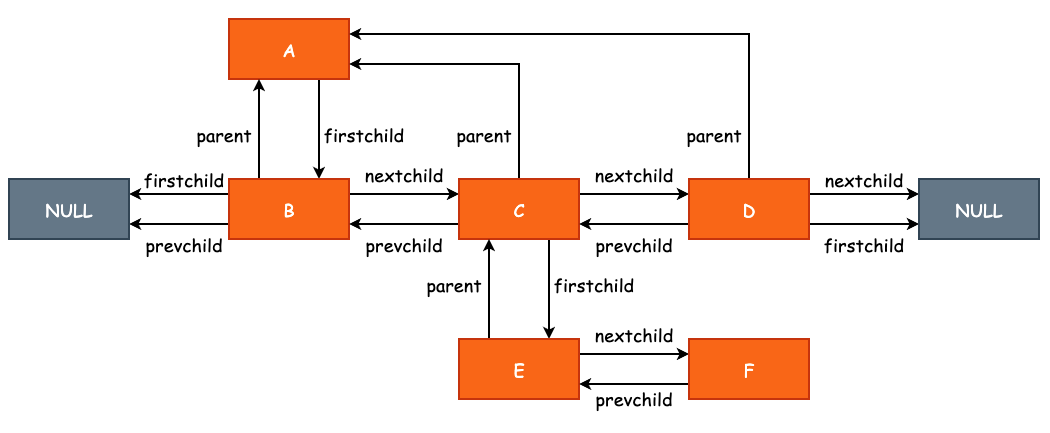
因此,MemoryContextData 最重要的作用便是管理各个内存上下文之间的关联关系,在清除一个内存上下文时,将会遍历该节点的所有子节点并对其进行释放。
3. AllocSetContext
AllocSetContext 是 MemoryContextData 的具体实现,其核心职责为内存的分配和释放,内存上下文之间的关联关系由 MemoryContextData 保存。
3.1 Region-Based Memory Management
这里就有必要对 PostgreSQL 的内存管理进行进一步地说明。PostgreSQL 将内存分为内存块(Block)和内存片(Chunk),其中内存块是通过 malloc() 这一库函数调用取得的。而一个内存块中将会有一个或者多个内存片,内存片才是 PostgreSQL 的最小存储单元。简单的理解就是 PostgreSQL 首先向操作系统要一块比较大的内存(Block),然后在对这一块大内存进行切割(Chunk),把切割之后的内存返回给调用方。
这么做的目的一方面是为了减少系统调用,在下一次的内存分配时即可直接返回给调用方,而无需进行系统调用。另一个作用就是减少额外的系统内存占用,因为 malloc() 所返回的内存必须要有 Header(或者叫 Cookie) 记录其内存总大小, 否则 free() 将无法正常工作。
下图为 VC6 编译器在进行 malloc 调用时返回的结果的内存布局,其中 Debug Header 只有在 Debug 模式下才会出现,但是所分配内存区域的首、尾两端的 Cookie 却必不可少,因为它记录了一次 malloc 所分配的总内存,总计占用 8 Bytes。
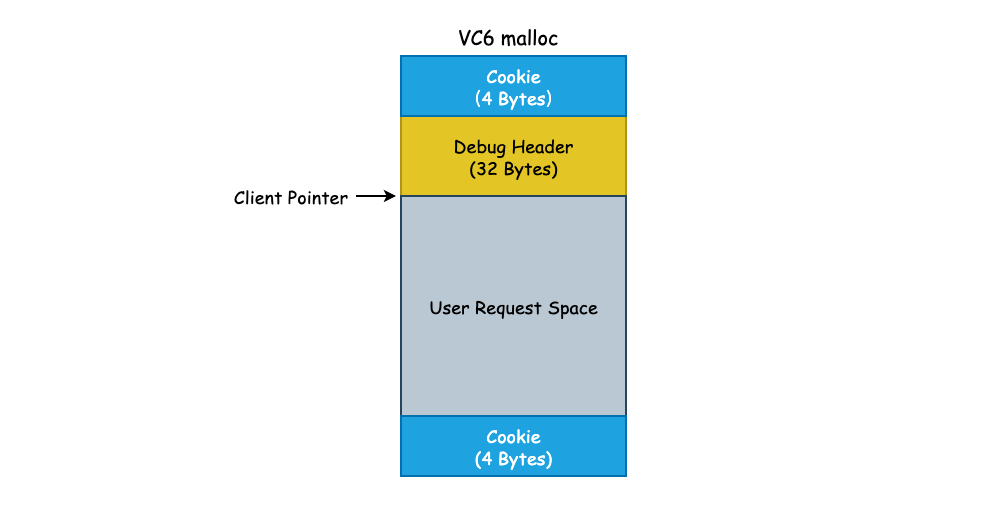
也就是说,我们每次使用 malloc() 申请 24 Bytes 的内存,系统最少消耗 32 Bytes 的内存,那么对于应用程序来说,内存的实际使用率为 24/32 = 0.75。如果我们有 100 万个 malloc 调用,那么将会有非常多的内存用于 Cookie 中,如此一来内存使用效率将会非常之低。
因此,PostgreSQL 使用了一种名为 Region-Based Memory Management 的内存管理方式,原理其实非常简单: 使用 malloc 申请较大的内存块,然后将该内存块切割成一个一个的小的内存片,将内存片返回给调用方。当调用方使用完毕返还时,并不会直接返回给操作系统,而是添加至 Free List 这一空闲链表的指定区域内,以用于下一次的内存分配。
3.2 基本数据结构
接下里就来揭开 AllocSetContext 的神秘面纱,其结构如下所示:
typedef struct AllocSetContext
{
MemoryContextData header; // header 信息,保存了内存上下文之间的关联关系
AllocBlock blocks; // 当前内存上下文中所有内存块所组成的双向链表
AllocChunk freelist[ALLOCSET_NUM_FREELISTS]; // 当前内存上下文中空闲内存片的数组
Size initBlockSize; // 初始内存块的大小
Size maxBlockSize; // 允许申请的最大内存块大小
Size nextBlockSize; // 下一个要分配的内存块大小
Size allocChunkLimit; // 分配内存片的尺寸阈值
AllocBlock keeper; // 保留在 keeper 中的内存块在上下文重置时会保留,只做重置操作,而不进行删除
int freeListIndex; // 在 context_freelists 中的顺序。
// 0 表示默认 freeList,1 表示小内存 freeList,-1 表示不需要进入 freeList
} AllocSetContext;
initBlockSize 和 maxBlockSize 在创建内存上下文时即被初始化,并且在初始化时 initBlockSize 和 maxBlockSize 具有相同的值。nextBlockSize 表示下一次分配的内存块的大小,在进行内存分配时,如果需要一个新的 Block,那么该内存块的大小将采用 nextBlockSize 的值。通常来说,nextBlockSize 在每次分配新的 Block 时都会以 2 倍的幅度增长,但最大不能超过 maxBlockSize:
set->nextBlockSize <<= 1; // 设置为上一次的两倍
if (set->nextBlockSize > set->maxBlockSize)
set->nextBlockSize = set->maxBlockSize; // 若超过阈值,则按阈值计算
AllocSetContext 的整体概览如下图所示:
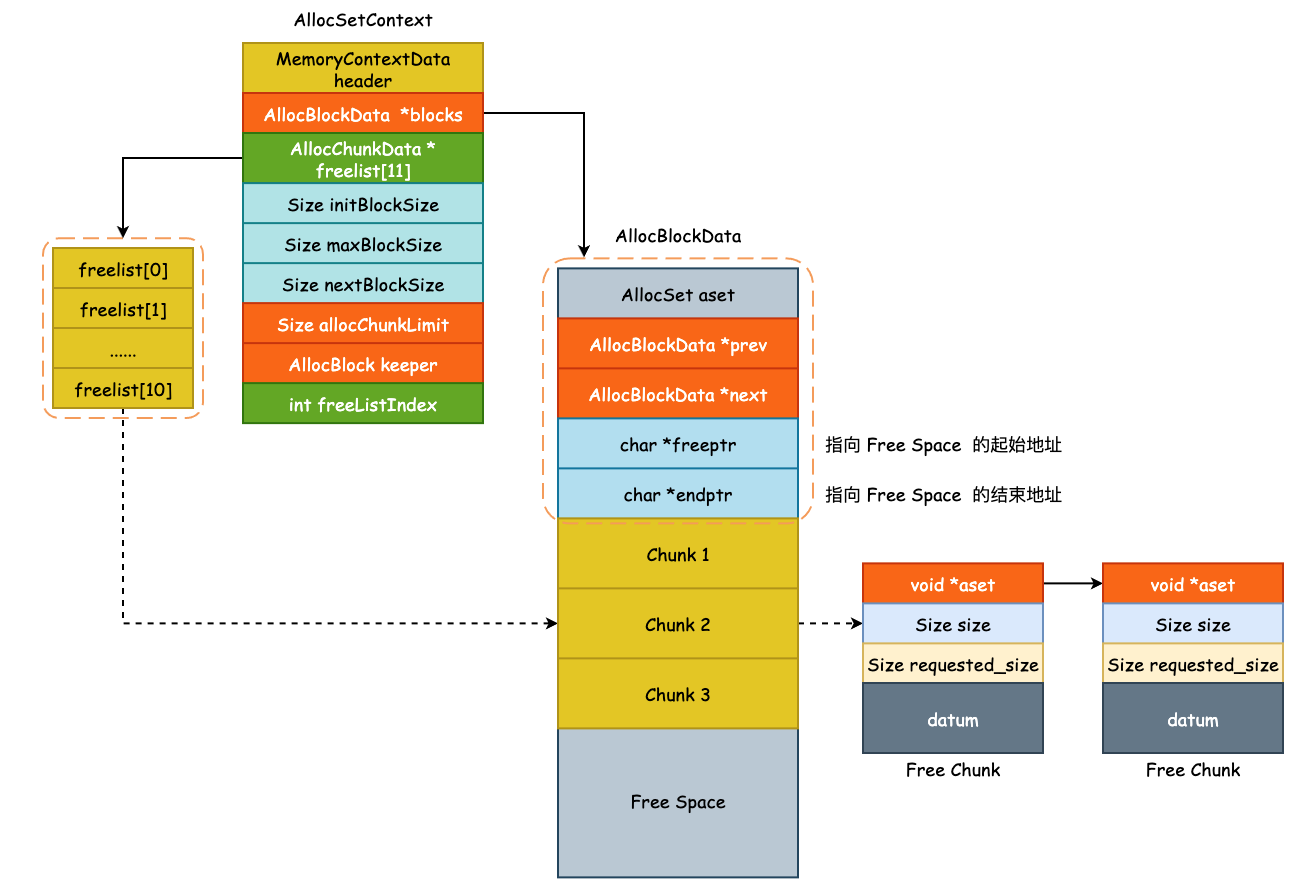
AllocBlockData 就是我们上面所说的大的内存块,由 malloc() 调用申请。而 AllocChunkData 则是小的内存片,一个 Block 中将会有一个或者多个内存片,空闲内存片之间使用单向链表这一数据结构保存。
另外,在源码中我们可以看到 AllocBlockData、AllocBlock 以及 AllocChunkData 和 AllocChunk,后者其实是前者的指针类型,只不过是一个 typedef 而已:
typedef struct AllocBlockData *AllocBlock;
typedef struct AllocChunkData *AllocChunk;
blocks 中保存了指向 AllocBlockData 节点所组成的双向链表的 Header 节点:
typedef struct AllocBlockData
{
AllocSet aset; // 该内存块所处的 AllocSetContext
AllocBlock prev; // 前驱指针
AllocBlock next; // 后继指针
char *freeptr; // 指向该内存块空闲区域的首地址
char *endptr; // 指向该内存块空闲区域的结束地址
} AllocBlockData;
前面我们已经知道了一个内存块(Block)中会被切割成一个或者多个内存片(Chunk),那么当切割出去一部分内存片之后,就需要知道这一个内存块还有那些空闲区域可供切割,freeptr 和 endptr 这两个指针就组成了带有边界的空闲区域,那么下一次就知道从哪儿开始切割内存片了。
每个内存片会包含一个头部信息,用于保存元信息,其结构如下:
typedef struct AllocChunkData
{
Size size; // 内存片的实际大小,以 2 的幂为大小进行向上取整
Size requested_size; // debug 使用
void *aset; // 该指针有两个作用,使用时指向 AllocSet,空闲时作为 next 指针链接其空闲链表
} AllocChunkData;
其中由 aset 指针组成的空闲内存片链表(freelist)相当重要,这些空闲内存片将用于再分配,并且有着多种不同大小的内存片以供分配。
freelist 数组的大小默认为 11,能够保存 11 种不同大小的空闲内存片,对于数组的第 K 个元素,其保存的内存片大小为 2^(K+2) 字节。K 从 1 开始取值,也就是说,freelist 数组中最小的内存片大小为 8 Bytes,最大的内存片为 8192 bytes(默认情况下),相同大小的内存片由链表链接:
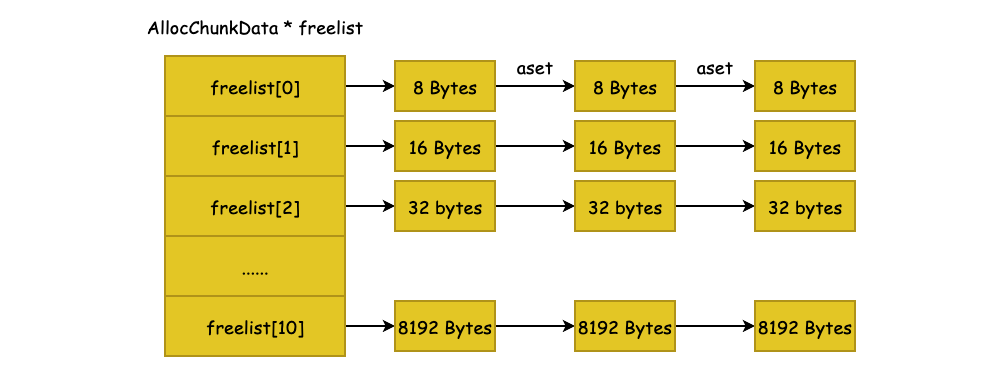
值得注意的是,所有 freelist 中的内存片的大小都为 2 的指数。当需要一个大小为 size 的内存时,将会根据向上取整的规则取出 freelist 中的空闲内存片。如果所申请的内存大小超过了 allocChunkLimit 字段的值,那么此次内存分配将会申请一个新的独立的内存块,并且在该内存块中只存放这一个内存片。当内存片被释放时,将整个内存块一并释放,不再追加至 freelist 空闲链表中。
4. 内存分配的实现细节
在 PostgreSQL 中,所有内存的申请、释放和重置都是在内存上下文中进行的,因此不会直接使用 malloc()、realloc() 和 free() 系统调用函数,而是使用 palloc()、repalloc() 和 pfree() 来实现内存的分配、重分配和释放。
4.1 内存的分配
内存的分配由 AllocSetContext 中的 AllocSetAlloc() 函数实现,即在 palloc() 方法中,实际上会调用 AllocSetAlloc() 方法:
void * palloc(Size size)
{
void *ret;
// 在当前内存上下文中进行内存分配
MemoryContext context = CurrentMemoryContext;
// 将 isReset 标志位设置为 false,那么在释放内存上下文时就需要清理其内存
context->isReset = false;
// 此处为多态实现,目前只有 AllocSetAlloc() 这一个实现
ret = context->methods->alloc(context, size);
if (unlikely(ret == NULL))
{
// 此处将打印 OOM 错误信息
}
return ret;
}
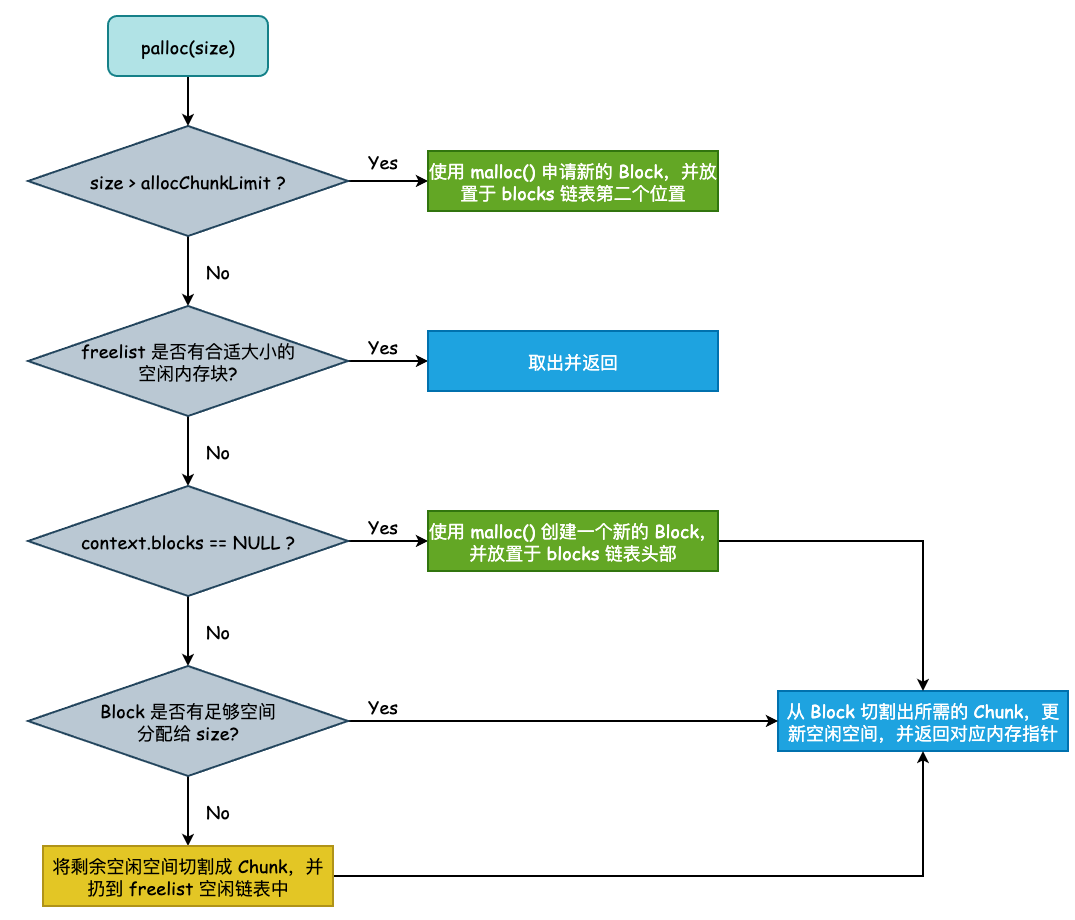
而在 AllocSetAlloc() 方法中,则会首先判断所申请的内存大小 size 是否大于 allocChunkLimit,若大于该值,则无法从 freelist 空闲内存片链表中取出空闲内存片,必须调用 malloc() 重新分配新的内存块。当然,即使 size 小于等于 CHUNK_LIMIT 阈值,如果 freelist 没有多余的空闲内存片的话,依然需要向 OS 申请内存:
4.1.1 当申请的内存大小超过了 allocChunkLimit 阈值
// 若 size 大于 allocChunkLimit 阈值,则需申请新的内存块
if (size > set->allocChunkLimit)
{
// 字节对齐
chunk_size = MAXALIGN(size);
// 除开申请的内存片以外,还需要为 AllocBlockData 和 AllocChunkData 预留空间
blksize = chunk_size + ALLOC_BLOCKHDRSZ + ALLOC_CHUNKHDRSZ;
// 向 OS 申请内存,这里使用的是 malloc
block = (AllocBlock) malloc(blksize);
if (block == NULL)
return NULL;
// 更新计数器
context->mem_allocated += blksize;
// 设置内存块信息
block->aset = set;
// 此时将不会有空闲空间用于切割更多的 Chunk 了,因此 freeptr 和 endptr 将指向末尾
block->freeptr = block->endptr = ((char *) block) + blksize;
// 设置内存片信息
chunk = (AllocChunk) (((char *) block) + ALLOC_BLOCKHDRSZ);
chunk->aset = set;
chunk->size = chunk_size;
// 需要将该内存块添加至上下文的 blocks 双向链表中,以便后续的释放
if (set->blocks != NULL)
{
// 链表头不为空,则将该 Block 插入至双向链表的第二个位置。
// 这是因为链表的第一个 Block 通常用于切割 Chunk,而该 Block 显然没有能力再切割
block->prev = set->blocks;
block->next = set->blocks->next;
if (block->next)
block->next->prev = block;
set->blocks->next = block;
}
else
{
// 链表头为空,则将其插入至链表头
block->prev = NULL;
block->next = NULL;
set->blocks = block;
}
return AllocChunkGetPointer(chunk);
}
4.1.2 当申请的内存大小未超过 allocChunkLimit 阈值,且 freelist 有空闲内存片
紧接着我们来讨论最简单的情况,即 size <= allocChunkLimit 并且 freelist 中存在空闲内存片,此时只需要从 freelist 中计算出对应的 slot,然后从链表摘下一个内存片返回给调用方即可:
// size <= allocChunkLimit
// 计算 size 所对应的 freelist index
fidx = AllocSetFreeIndex(size);
// 获取 index 所对应的内存片链表
chunk = set->freelist[fidx];
if (chunk != NULL)
{
Assert(chunk->size >= size);
// 使 header 指向下一个链表元素
set->freelist[fidx] = (AllocChunk) chunk->aset;
// 设置内存上下文信息
chunk->aset = (void *) set;
return AllocChunkGetPointer(chunk);
}
4.1.3 当前内存上下文所保存的 blocks 不为空,但没有足够空间
若当前内存上下文的 Block 中没有足够的内存空间来分配此次内存时,按照基本逻辑应该重新创建一个 Block,然后切割出对应的 Chunk 给用户。但是在这之前,当前 Block 中可能仍然有空闲空间,我们可以把这部分的空间切割成 Free Chunk 扔到 freelist 中,做到物尽其用,这部分代码不太核心,故不再此处详细分析。
4.1.4 当前内存上下文所保存的 blocks 为空
若当前内存上下文所保存的 blocks 为空,或者是经过了 4.1.3 步骤将旧的 Block 切割完毕,此时我们就需要创建一个新的 Block,新的 Block 通常为上一次分配的 Block 大小的 2 倍,但又不会超过 maxBlockSize:
// 此时需要创建一个新的内存块
if (block == NULL)
{
Size required_size;
blksize = set->nextBlockSize;
// 设置下一次要分配的 Block 大小为当前的 2 倍
set->nextBlockSize <<= 1;
// 若超过了阈值,则按阈值取值
if (set->nextBlockSize > set->maxBlockSize)
set->nextBlockSize = set->maxBlockSize;
// corner case: 若 blksize 小于预设的 Block 大小,则需要继续扩大 Block 大小
required_size = chunk_size + ALLOC_BLOCKHDRSZ + ALLOC_CHUNKHDRSZ;
while (blksize < required_size)
blksize <<= 1;
/* Try to allocate it */
block = (AllocBlock) malloc(blksize);
// 申请失败时使用更小的 blksize 进行重试
while (block == NULL && blksize > 1024 * 1024)
{
blksize >>= 1;
if (blksize < required_size)
break;
block = (AllocBlock) malloc(blksize);
}
if (block == NULL)
return NULL;
// 更新计数器
context->mem_allocated += blksize;
// 设置内存块信息
block->aset = set;
block->freeptr = ((char *) block) + ALLOC_BLOCKHDRSZ;
block->endptr = ((char *) block) + blksize;
/* Mark unallocated space NOACCESS. */
VALGRIND_MAKE_MEM_NOACCESS(block->freeptr,
blksize - ALLOC_BLOCKHDRSZ);
// 将该 block 插入至 blocks 链表的头部,而非第二个位置,因为下次 Chunk 切割需要从此 Block 开始
block->prev = NULL;
block->next = set->blocks;
if (block->next)
block->next->prev = block;
set->blocks = block;
}
4.1.5 最后,在有充足空闲空间的 Block 中切割 Chunk
当前置准备工作都做完之后,我们就可以在内存块中切割出所需要的 Chunk 了:
// 从 freeptr 开始切割出一个 Chunk
chunk = (AllocChunk) (block->freeptr);
// 更新 freeptr 指针指向
block->freeptr += (chunk_size + ALLOC_CHUNKHDRSZ);
Assert(block->freeptr <= block->endptr);
// 设置内存片信息
chunk->aset = (void *) set;
chunk->size = chunk_size;
return AllocChunkGetPointer(chunk);
最后,我们用一张简单的流程图来描述内存分配的大致过程:
4.2 内存的释放
上下文内存的释放要比内存分配简单许多,只需要讨论如下两种情况即可:
- ChunkSize > allocChunkLimit: 直接调用
free()进行释放 - ChunkSize <= allocChunkLimit: 将 Chunk 直接添加至
freelist空闲链表中即可
5. 关于内存上下文的切换
我们能够在源码中经常看到 MemoryContextSwitchTo() 这个函数的调用,其作用就是将当前内存上下文切换至指定的内存上下文之中。
一个简单的例子就是系统表的缓存内存申请。当我们执行一个 Query 并且需要使用 System Catalog 时,通常会将读取到的 Catalog 缓存到内存中,以便下次更快地读取。那么这部分的内存就肯定需要在 CacheMemoryContext 这一内存上下文中申请,而不能在 MessageContext 或者是 CurTransactionContext 等内存上下文中申请。
static inline MemoryContext
MemoryContextSwitchTo(MemoryContext context)
{
MemoryContext old = CurrentMemoryContext;
CurrentMemoryContext = context;
return old;
}
由于该函数本身比较短小并且经常使用,因此在定义时添加了 inline 关键字,在编译阶段直接展开。
这里以我曾经在 Greenplum 中遇到的一个关于内存未在正确的内上下文中被申请而导致出现 SEGSEGV 的例子来说明切换至正确上下文的必要性。
Greenplum 是一个 MPP 架构数据库,也就是说一个 table 中的数据可以根据某种算法存储在不同的 segment 节点之上。最常用的分布策略就是哈希分布,Greenplum 使用 Jump Consistent Hash 算法根据用户指定的分布键尽可能均匀地将数据分布在不同的节点之上。其次还有不常用的 Randomly 随机分布,以及 Replicated 复制分布。
Greenplum 使用 GpPolicy 这一结构体来保存一个 table 的分布策略,同时也会被写入 RelationData 这一结构体中。在 Expand partition table leaves in parallel. 这个 commit 的 ATExecExpandPartitionTablePrepare() 函数中修改了 table 的分布策略,代码本身也非常容易理解:
// 根据现有分布策略复制一个出来
GpPolicy *root_dist = GpPolicyCopy(rel_dist);
// 修改分布策略的 segments 数量
root_dist->numsegments = new_numsegments;
// 将 relation 的分布策略替换成 root_dist
GpPolicyReplace(relid, root_dist);
// 更新 relation 的 rd_cdbpolicy 指针
rel->rd_cdbpolicy = root_dist;
但是这一段代码会导致数据库在后续的运行中产生空指针访问,从而触发 Segment Fault 错误。其根本原因就在于 GpPolicyCopy 会在当前内存上下文中申请内存,而对于一个 ALTER TABLE 语句而言,执行语句的内存上下文通常为 PortalHeapMemory,Portal 结束后内存即会被释放。也就是说,rd_cdbpolicy 其实当前语句结束后因为内存上下文的释放而被设置为 NULL,那么如果下一条语句访问了 rd_cdbpolicy 的话,就会因为引用空指针而 PANIC。
因此,我们必须保证 rd_cdbpolicy 和 rel 具有相同的生命周期,做法就是将当前上下文切换至 rel 所在的内存上下文中,然后再为 GpPolicy 申请内存:
// 通过 GetMemoryChunkContext 方法获取到 rel 所在内存上下文
oldcontext = MemoryContextSwitchTo(GetMemoryChunkContext(rel));
// 在 rel 所在内存上下文中复制出一个 GpPolicy 出来
new_policy = GpPolicyCopy(rel->rd_cdbpolicy);
new_policy->numsegments = new_numsegments;
// 切换至原有内存上下文,此处为 PortalHeapMemory
MemoryContextSwitchTo(oldcontext);
GpPolicyReplace(relid, new_policy);
rel->rd_cdbpolicy = new_policy;
更多的细节可参考 Pull Request: Fix PANIC error in ALTER TABLE xxx EXPAND PARTITION PREPARE 以及 Avoid changing rd_cdbpolicy at relcache invalidation.