优先队列为动态变化的数据赋予了高效且准确的排序能力, 尽管有非常大规模的数据, 二叉堆所实现的优先队列依然能够表现出色。
1. 为什么要有优先队列
队列是一种先进先出的数据结构, 所有的入队元素的优先级都是一样的, 完全遵循先进先出的规则。 然而在实际中这种绝对的公平有时需要被打破。 例如操作系统的进程调度, 在当前环境下, 会有优先级调度高的进程, 例如IDE的运行, 浏览器的运行。 一些进程的调度优先级并不会很高, 例如邮件系统。 系统中的进程数量和对应的优先级是一个动态变化的过程, 不能够简单的对所有进程排序, 而后选取优先级最高的进程, 而是需要维护一个优先级队列。
2. 优先队列的实现方式
假设使用数组来实现优先队列, 并维持该数组的有序性。 那么取出优先级最大的元素可以在O(1)时间内完成, 而插入一个元素的时间则不定。 采用二分查找的方式查找元素的时间复杂度为O(logN), 插入元素所导致的数组元素的移动平均时间复杂度为O(N), 结合起来总的时间复杂度为O(NlogN)。
如果使用链表来实现的话, 可以使用跳跃表来维护一个有序链表。 出队操作可以在O(1)时间内完成, 入队操作最坏情况为O(N), 平均时间复杂度为O(logN)。 实际上在数据量较小的时候, 采用跳跃表实现优先队列也是一个不错的选择, 但是当数据量比较多的时候, 由于跳跃表需要除有序链表本身所需要的空间以外, 还需要一些额外的空间来存储每层的索引, 所以此时跳跃表的综合表现就会降低。
平衡二分搜索树或者红黑树是一个比较好的选择, 入队以及出队操作平均时间复杂度均为O(logN), 但是树的随机访问性要差一些, 在有些时候, 树所实现的优先队列也是一个比较好的选择。
在更多的情况下, 我们采用底层由数组所实现的堆结构来实现优先队列。
3. 二叉堆
二叉堆是一颗完全二叉树, 完全二叉树定义起来有些费劲, 图示会更加清晰一些:
| 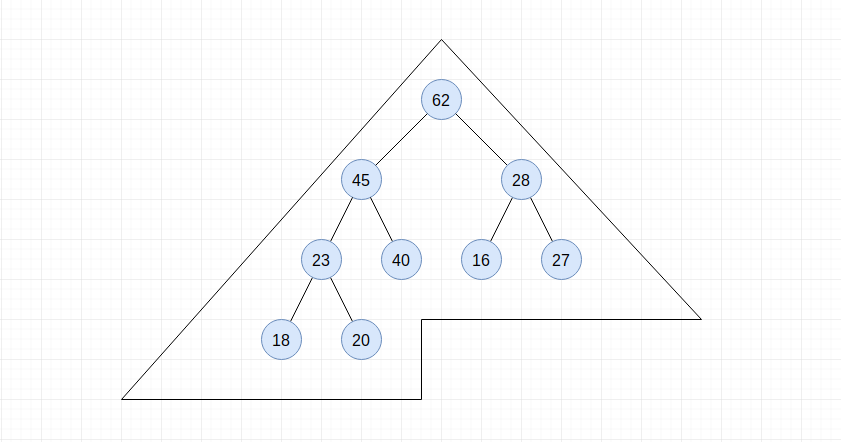 |
在一棵完全二叉树中, 最后一层所缺失的叶子节点均在整棵树的右侧。 并且在一个最大二叉堆中, 父节点元素值要大于其子孙节点的元素值。
由于二叉堆是一颗完全二叉树, 那么我们可以使用数组来进行存储, 如下图所示:
| 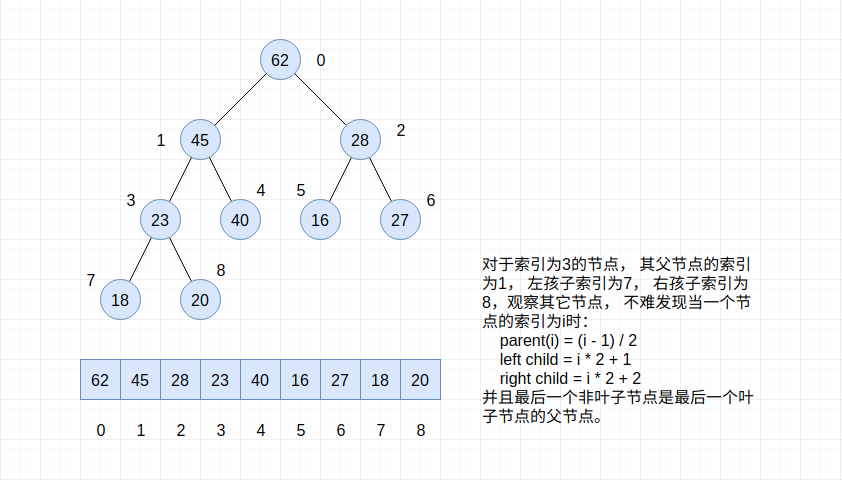 |
使用数组进行存储的话, 完全可以使用索引的运算来获取一个节点的父节点, 以及左右孩子节点的索引, 省去了指针的存储空间。
所以, 基于此特性, 我们可以大致的定义出PriorityQueue这个类所拥有的属性以及部分方法:
class PriorityQueue:
def __init__(self, data=[]):
# 这里使用了一个mutable变量作为默认参数, 所以对其进行内存的重新分配, 会有一定的内存浪费, 但是会增加一些灵活性
self.data = list(data)
def get_parent(self, index):
# 获取父节点索引
if index == 0:
raise ValueError("Index 0 doesn't have parent node")
return (index - 1) // 2
def get_left_child(self, index):
# 获取左子节点索引
return 2 * index + 1
def get_right_child(self, index):
# 获取右子节点索引
return 2 * index + 2
def swap(self, a, b):
# 交换数组中两个元素的位置, 在上浮和下沉操作中都会用到
self.data[a], self.data[b] = self.data[b], self.data[a]
3.1 向堆中添加元素
首先将该元素扔到数组末尾, 然后执行上浮操作即可。

def add(self, value):
self.data.append(value)
self.sift_up(len(self.data) - 1)
def sift_up(self, index):
# 上浮操作
while index > 0 and self.data[self.get_parent(index)] < self.data[index]:
self.swap(self.get_parent(index), index)
index = self.get_parent(index)
3.2 取出堆中最大元素
既然是最大堆, 那么堆顶就是最大的元素, 直接弹出即可。 在弹出之后仍然需要维护堆的性质, 此时将堆最后一个叶子节点置于堆顶, 并执行下沉操作即可。
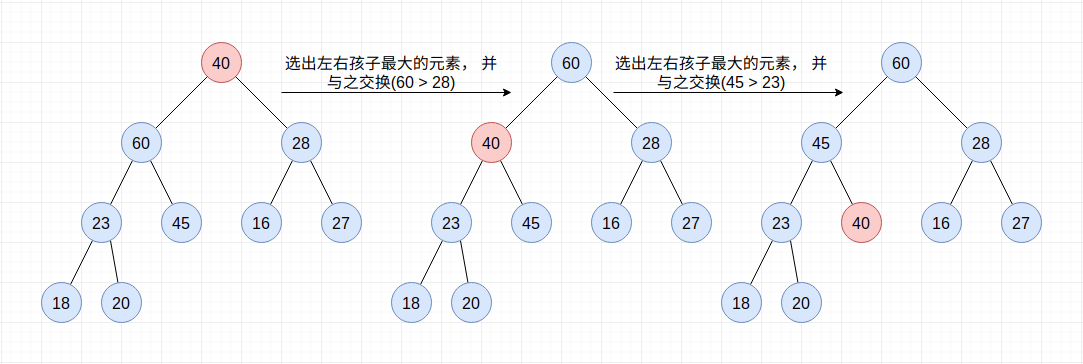
下沉操作要比上浮操作稍微复杂一些, 主要是需要与左右孩子进行比较, 取较大者进行交换。
def get_max(self):
if len(self.data) == 0:
raise ValueError("Heap is empty")
value = self.data[0]
self.swap(self.data[0], self.data[-1])
self.data.pop(-1)
self.sift_down(0)
return value
def sift_down(self, index):
# 下沉操作, 当下沉到没有左孩子或者是当前节点数值大于左右孩子时, 下沉结束
while self.get_left_child(index) < len(self.data):
j = self.get_left_child(index)
if j + 1 < len(self.data) and self.data[j] < self.data[j+1]:
j = self.get_right_child(index)
if self.data[j] < self.data[index]:
break
self.swap(index, j)
index = j
3.3 将已有数组进行堆化操作
给定一个数组, 将其整理为堆。 这个过程常常称为heapify, 从最后一个非叶子节点开始, 对每一个非叶子节点均进行下沉操作即可。 之所以进行下沉操作而不是上浮操作的理由也非常简单, 如果进行上浮操作的话, 首要的冲突就是最后一层的叶子节点无法顾及, 并且上浮操作并不一定能保证最后的结果仍然是一个堆。

def heapify(self, data):
# 给定一个数组, 采用heapify的方式将其整理成堆
self.data = list(data)
last_non_leaf_node_index = self.get_parent(len(self.data) - 1)
for i in range(last_non_leaf_node_index, -1, -1):
self.sift_down(i)