当系统的某些行为涉及到资金与资产的数据变更时,常常会为其增加操作日志,便于后续的问题排查。例如红包的使用明细,银行转账的详细记录等等。操作日志记录这个需求看起来很简单,但是深挖下去,依然能找到很有趣的东西。
1. 需求
既然是操作日志,势必要记录谁对什么进行了怎样的操作,抽象出来的字段就有operator(操作人),action(创建、修改等行为),entry(实体, 通常会用实体id来代替)。
MySQL-binlog的日志格式有FULL和MINIMAL两种,前者记录了所有的字段,后者只记录了更新的部分字段。那么对于操作日志而言,同样需要考虑是记录更新前后的所有数据字段,还是只记录更新的字段。操作日志的数据当然是越详细越好,既然都要做这个需求了,那就一步到位。
所以说,本篇文章的日志格式即为数据库数据的增量版,并且在原有数据字段上进行稍许拓展,进行更加详细的记录。也可以认为这就是记录了所有的数据版本库,此时添加一个版本号即可。
2. 实现
理论上来讲实现有两种,一种是业务层面实现,一种是使用日志解析工具来解析二进制日志,但是该实现方式非常依赖具体的存储实现,像MySQL和Oracle的解析策略是不一样的,如果使用了MongoDB作为主库存储,数据文件解析起来就更费劲了。
从项目维护的角度来看,业务层实现在编码完成之后,几乎不需要花太多的精力维护。但是日志解析或者是数据文件解析工具,却需要花大量的人力和时间来维护(看看canal)。
从易拓展的角度来看,业务层的实现只需要稍加抽象,就可以随意的更换或者添加数据存储源。而日志分析的实现如果需要更换数据源的话,迁移的工作量可能相当庞大。
从效率的角度来看,业务层的实现效率确实会低于日志解析的实现。
综上考虑,业务层实现是最佳的方式,方便维护,方便拓展,在效率上虽然会对原有系统造成影响,但是可以通过其它的方式进行补偿。
3. 实现细节
在具体的实现之前,首先来看一下常见Web请求的基本流程,当然,这里只针对创建、修改和删除操作:

当对创建请求进行操作日志记录时,完全可以将经过表单验证以及逻辑处理后的数据直接写入到日志记录库,并添加一些附属信息,如操作人,操作的动作(create),来源IP等等。
但是对于更新操作呢? 通常只会进行部分字段的更新,而后直接使用
update ... set field = value where ...;
进行部分字段或者是批量更新。但是为了记录更新后的完整数据,那么就需要在更新后再将数据取出,添加附属信息,并插入日志记录库。如此一来相比原来,多了一次查询操作。
如果不使用update语句,使用instance.save方式呢? 即先将数据取出,而后更新数据,将更新的数据写回DB并插入操作日志。
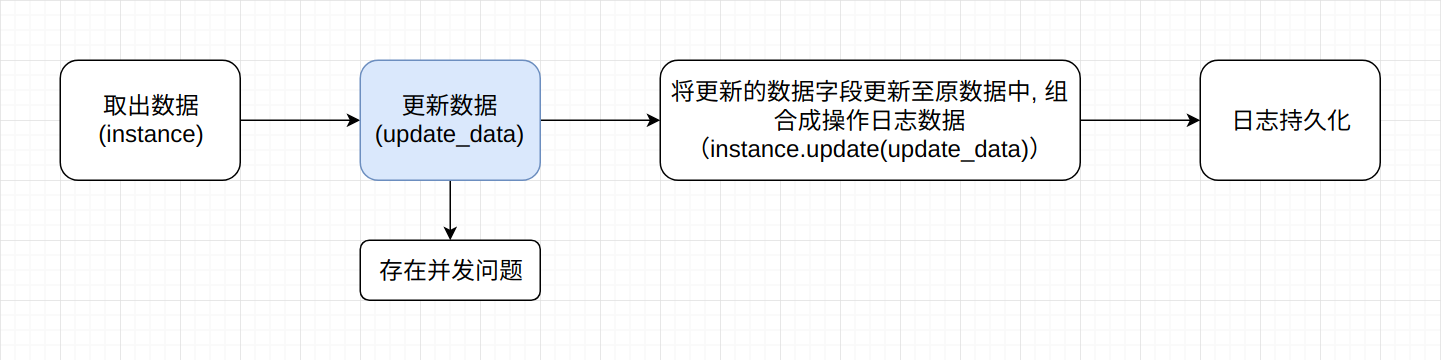
在使用ORM的应用中,这样的代码其实很常见,一个最大的问题就是并发时的数据问题,先更新的语句可能会覆盖掉另外一条后更新的语句,导致数据混乱。
原因就在于取出数据-更新数据不是一个原子性的操作,底层的数据库因为并发执行导致多条语句的执行顺序并不受程序控制。所以我们要么寻找一种能够原子性执行的方式,要么对数据添加行锁。首先来看行锁的方式:
使用select for update对数据添加行锁,在一个事务内,只能由当前事务对其进行更新, 这样一来就不会有并发问题了。但是这种方式相比于第一种方式,额外的增加了行锁的持有时间,在大量的并发更新时,很有可能产生雪崩效应。
如果使用版本控制的乐观锁实现,虽然也可以达到目的,但是在大量并发的情况下可能会导致许多的更新都会失败,而后全部进行重试流程,导致恶性循环。
4. 事务隔离
在上面的讨论中,不管是先更新,还是先取出数据再更新,都面临着同一个问题: 并发。并发导致了SQL语句并不会向我们预期的那样执行,前脚取出的数据可能后脚就被更新了。所以我们需要一个机制来协助我们对抗并发,事务。
单纯的事务仅具有原子性,即要么全部成功,要么全部失败的特性。想要满足我们的需求还需要一定的事务隔离级别。
REPEATABLE READ该事务隔离级别保证了在同一个事务内,所读取到的数据不受其它事务语句的影响, 同样也是MySQL默认的事务隔离级别。
所以不管是先更新还是先取数据,只要在同一个事务内执行,就不会存在数据污染问题,保证了数据的准确与完整性。
5. AOP的实现
面向切面编程更进一步地理解其实就是函数式编程,纵观Spring Boot AOP以及Python中的装饰器,都是函数的注册与调用,只是语言间的具体实现不同而已。Python存在@语法糖,更加的灵活和方便。而对于Golang和Java而言,就需要自己进一步的进行函数封装和调用了。
包括像hook(钩子)一类的技术实现,最终也是函数的注册与调用。比如Django中的singal(信号量),虽然说是发布-订阅模式,但是本质仍是函数的调用。只不过没有把具体的逻辑写在一个地方,而是使用某种其它方式进行解耦了而已。
所以,写一个简单的AOP是一件非常easy的事情,处理好异常和重试机制就好。
6. 日志存储源
一个系统中对数据处理优先程度是不同的,类似于转账记录、红包使用记录等数据,必须进行完备的数据持久化,并且能够在灾难时进行迅速恢复。此时可使用可靠性较强的关系型数据库,如MySQL,PG等。
当数据的要求较低,并且数量比较庞大时,可采用Elasticsearch进行存储和查询。
那么业务层在具体实现时,就需要能够支持多种日志存储源,此时面向接口编程又是最佳的选择。
7. 持续优化
前面提到了由于需要记录数据操作日志的原因,需要在更新、删除等操作后多一次额外的数据查询,并且需要将完整的日志数据持久化至日志存储源,相当于多了两次网络传输。
如何将这两次网络传输所花费的时间降至最低,是本小结要讨论的内容。
数据库数据组织形式分为聚集索引和非聚集索引,聚集索引的组织方式使得B+Tree的叶子节点即数据,而非聚集索引的叶子节点仍然是索引节点,需要多聚集索引B+Tree树高个I/O操作找到该索引节点的数据节点。所以说,使用主键进行查询和更新具有更高的效率。
对于常见的更新操作,通常不会使用主键来作为查找条件,这是由业务系统所决定的。所以说如果使用更新-查询的方式,无法使用主键进行查询来提高系统效率。相反,使用查询-更新的方式却可以。查询时使用非聚集索引进行查询,而后使用聚集索引来进行数据定位和更新。
日志持久化可使用消息队列完成,重试机制可使用消息队列本身携带的重试实现,或者是对其进行封装,自行实现。
8. 批量更新问题
如果需要更新的行数不止一条,而是有很多条时又该如何处理? 取出数据后遍历更新并生成操作日志吗?
在业务端写SQL一个比较忌讳的事情就是在for循环中对数据库进行操作,如此一来必定会有N次网络传输,跑起来的效率令人发指。
可以采用查询-业务端组装操作日志-更新的方式完成,伪代码如下:
# 开启事务
begin
result_list = Model.get(**kwargs)
# 生成批量日志
log_list = []
for instance in result_list:
ins_dict = Serialize(instance)
# 填充ip, 操作人等信息
log_list.append(ins_dict)
# 对多条数据进行更新
Model.update(**kwargs)
commit or rollback
# 事务成功提交后将日志提交至存储层
9. 小结
记录操作日志这个需求看起来很小,但是仔细的审视每一个操作内的细节,会发现这真是一个有趣的需求。涉及了数据库事务,事务隔离,索引,NoSQL与搜索引擎,消息队列,等等技术细节。