gRPC是一个高性能、通用的开源RPC框架,其由Google主要面向移动应用开发并基于HTTP/2协议标准而设计,基于ProtoBuf(Protocol Buffers)序列化协议开发,且支持众多开发语言。(这Ctrl-C/V也是没有下限了….
1. Protocol Buffers
在早期,ProtoBuf主要用于解决Google内部的服务器高低版本的兼容性问题,后来由于其高效的数据传输效率被用于gRPC的传输数据格式。
相较于XML以及Json,ProtoBuf在传输和存储时由于其体积更小,所以效率更高,并且序列化的速度也比Json的序列化速度更快,原因将在后续部分介绍。
除此之外,ProtoBuf的最大特点就是支持向后兼容。如果使用Json或者XML的话,需要应用程序自行处理新旧版本数据格式之间的兼容性。而ProtoBuf则不需要破坏已经被部署的服务结构,ProtoBuf会帮助用户处理好高低版本的兼容性问题。
1.1 ProtoBuf所支持的数据类型
对于基本数据类型,如int,float,double,string,bool以及bytes,ProtoBuf均支持定义以上数据类型。对于int类型的数据,ProtoBuf对其进行了额外的拓展,在不同的场景使用不同的整型将会有不同的运行效率。
| ProtoBuf Type | Explain |
|---|---|
| int32 | int32最大支持4字节的整型数字,编码负数时效率较低 |
| int64 | int32最大支持8字节的整型数字,编码负数时效率较低 |
| uint32 | uint32最大支持4字节的无符整数 |
| uint64 | uint32最大支持8字节的无符整数 |
| sint32 | sint32最大支持4字节的有符整数,编码负数时效率更高 |
| sint64 | sint32最大支持8字节的有符整数,编码负数时效率更高 |
| fixed32 | 不使用可变长度方式进行编码,总是传输4字节,在编码超过$2^{28}$数值的整数时效率更高 |
| fixed64 | 不使用可变长度方式进行编码,总是传输8字节,在编码超过$2^{56}$数值的整数时效率更高 |
除了上述的基本数据类型以外,ProtoBuf同时也支持列表,字典以及枚举类型的定义,再加上message类型支持嵌套定义,几乎可以说能够覆盖日常开发中的所有需求了。
1.2 ProtoBuf中的消息定义
message数据类型是ProtoBuf在序列化和反序列化中的最小单位,和C结构体非常类似。
message Response {
int32 code = 1;
string msg = 2;
int32 data = 3;
}
message中的字段类型和字段名称无需赘述,值得关注的是后面的Field Numbers,字段序列号。该序列号将会在数据存储和传输时用于指代message中所定义的字段,即对源数据编码成ProtoBuf格式数据后,字段名称将会被舍弃,转而使用字段系列号进行代替,所以会说ProtoBuf并不是自描述的传输格式,同时也是数据体积更小的原因之一。
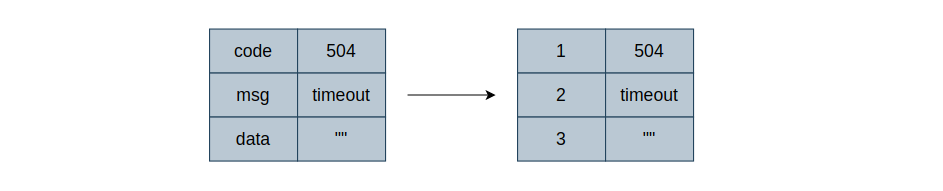
所以,一个message中的字段系列号必须唯一,同时范围必须在[$1$, $2^{29}-1$]之间。并且19000到19999之间的数值被ProtoBuf内部所用,也不可定义。
下面是一个使用了大部分数据类型的message定义:
enum UserStatus {
// 值为0的枚举值必须定义,因为这是ProtoBuf对枚举值的默认值
// 同时,该零值不应该被应用程序所使用,否则会出现歧义
USER_STATUS_INVALID = 0;
USER_STATUS_NORMAL = 1;
USER_STATUS_FROZEN = 2;
USER_STATUS_DELETED = 3;
}
message MainAddress {
string province = 1;
string city = 2;
string address = 3;
}
message UserInfo {
uint32 user_id = 1;
string mobile = 2;
repeated string extra_mobile = 3;
UserStatus status = 4;
MainAddress main_address = 5;
bool is_vip = 6;
}
1.3 ProtoBuf编码
ProtoBuf格式的数据体积更小的原因一方面归功于使用字段系列号来代替字段名称,另一方面则是因为对整型采用了可变长度编码方式,即使是指定了int32类型的数据也可能只使用一字节存储。
1.3.1 Base 128 Varints
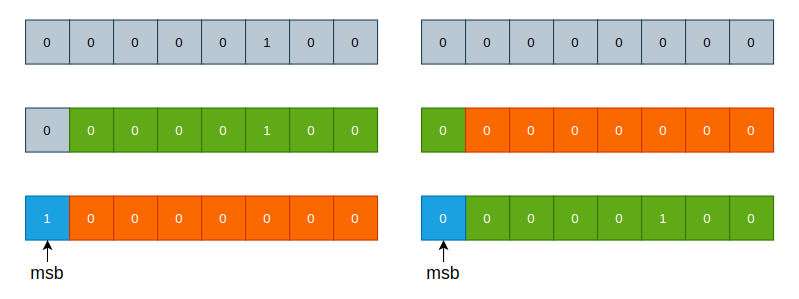
Varint使用一个或者多个字节表示一个数字,数字的值越小,所使用的字节数也会更小。其长度并不固定,所以称之为”可变长整数”。
Varint中的每个字节(最后一个字节除外)都设置了最高有效位(msb),用于表示后面还会有更多字节出现,所以Varint中的最后一个字节不会设置msb。由于首位被当做是msb使用,所以一个字节只有7位有效位。
例如数字1,可以使用1字节进行表示,那么其最高有效位即可设置为0:
0000 0001
对于多字节的数字,除了最后一个字节以外,其余字节的首位都应该置为1,以表示后续仍有字节。以数字1024为例,在一般情况下,1024需要使用2个字才能表示:
1024 = 0000 0100 0000 0000
现在来看下Varint的编码过程:
- 首先,1024超过了7位,所以必须使用至少2个字节表示,但是又小于14位,所以需要2个字节表示。按每7位取一个字节,若不够7位则用0补齐:
0000 0100 0000 0000 -> 0001000 0000000
- 将低字节写入到高字节,最后一个字节最高位补0,其余字节最高位补1,即为最终结果:
10000000 00001000
1.3.2 Message Structure
在ProtoBuf中,message结构其实就是一系列的键值对,只不过message在序列化成二进制时,对键和值进行了特殊的处理而已。
首先来看对键的处理,键的计算方式是(field_number << 3) | wire_type,根据键的计算公式可以看出,键的最后3位就是字段类型。field_number即为用户自定义的字段序列号,而wire_type则是一个由ProtoBuf所定义的对类型的”枚举”。:
| Write Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimited | string, bytes, embedded messages, packed repeated fields |
| 5 | 32-bit | fixed32, sfixed32, float |
值得注意是当wire_type为2时,序列化结果中还需要包含数据的长度,即length。
- 当
wire_type为0、1和5时,序列化的结果为key + 数据,数据长度由数据自描述。 - 当
wire_type为2时,序列化的结果为key + length + 数据,数据长度由length决定。
下面通过一个实际的例子看下Message Structure的编码形式:
syntax = "proto3";
message foo {
string bar = 5;
}
将bar的值设置为”Hello”,序列化后将得到以下结果:
052a 6548 6c6c 006f
ProtoBuf是小端字节序,阅读起来不是很方便,将其转换一下:
2a05 4865 6c6c 6f
其中4865 6c6c 6f为字符串”Hello”的16进制表示,那么2a05就是前面提到的key+length了。2a的二进制格式为101010,最后3位为010,转换成十进制结果是2,对应string类型的write_type。101转换成十进制结果为5,对应bar字段的field_number。length则由05确定,表示字符串的长度为5。
2. HTTP/2
HTTP/2协议在原有的HTTP/1协议版本之上进行了大幅度的修改,其传输效率大大提升,并且能够有效地降低服务端的资源消耗。
- 由文本传输改变为二进制数据传输,解析更加高效。
- 使用新的二进制分帧机制改变了客户端和服务端之间交换数据的方式,每个二进制帧可进行乱序传输,解决了HTTP/1中的首部阻塞问题。
- 对请求头部字段的压缩使得传输数据更小,传输效率更高。
为了更好的理解HTTP/2,首先要明确HTTP/1的缺陷之处,首当其冲的就是TCP连接数限制。在浏览器中,同一个域名下同时只能创建6~8个TCP连接,剩下的请求只能等待这些请求的返回。并且,每个TCP连接只能承载一次请求/响应,当初始发送的请求响应时间较长时,整个页面加载也会受到阻塞。
2.1 二进制分帧
在HTTP/1中,请求的数据以明文进行传输,例如:
GET / HTTP/1.1
Host: example.com
而在HTTP/2中,请求或者响应数据不再以文本的方式进行传输,而是直接使用二进制数据进行传输,使得解析更加高效。其原因在于HTTP/1是通过特殊符号,如空格,\r\n等特殊字符进行分割并解析的。而HTTP/2首先对数据进行了分类,将请求头和Payload分开,并且在每一个传输单元中都进行了标记。
HTTP/2的基本传输单元为帧(Frame),每一个都以固定的9个字节开头,后跟不定长度的Payload。Payload可以是用户传输的数据,也可以是协议本身携带的数据。
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
| R (1) | Stream Identifier (31) |
+=+=============================================================+
| Frame Payload (0...) ...
+---------------------------------------------------------------+
24+8+8+1+31,刚好为72位,即9字节。下面来看每一个字段的含义:
- Length: 表示Payload的长度,是一个24位的无符整数,单位为字节。也就是说,通常情况下一个帧最多能够传输2^14(16,384)个字节。如果想在一个帧中传输更多的数据,则可以通过传输
SETTINGS_MAX_FRAME_SIZE帧来改变基本大小。 - Type: 帧的类型,如
DATA帧、HEADERS帧。 - Flags: 该字段用于各类型的帧进行补充说明,表示特殊的含义。一个常见的标志就是
END_HEADERS,表示头数据已经结束。 - R: 预留位,并未使用。
- Stream Identifier: 流标识符,31位无符整数,作用将在下方描述。
2.2 多路复用
HTTP/2一个最重要的特性就是多路复用,即在一个TCP连接中同时传输多个请求或者是响应,而HTTP/1想要做到这一点的话,必须要建立多个TCP连接。
在HTTP/2中引入了”流”(Stream)的概念,对应HTT/1的话,其实就是一个请求: 在一个连接中发送多个请求其实就是发送多个流。而流又是由帧组成的,所以在帧中需要字段Stream Identifier来标记当前帧属于哪个流。
实现多路复用的逻辑概念就是流,和TCP流式传输不同的是,HTTP/2中的流只是一个逻辑上的概念,每一个流使用Stream Identifier进行标识。一个请求或者是响应在拆分成多个帧以后,将使用同一个流ID在连接中进行传输,接收方在接收到乱序传输的帧以后,按照流ID进行组装,即可得到一个完整的请求或者是响应。
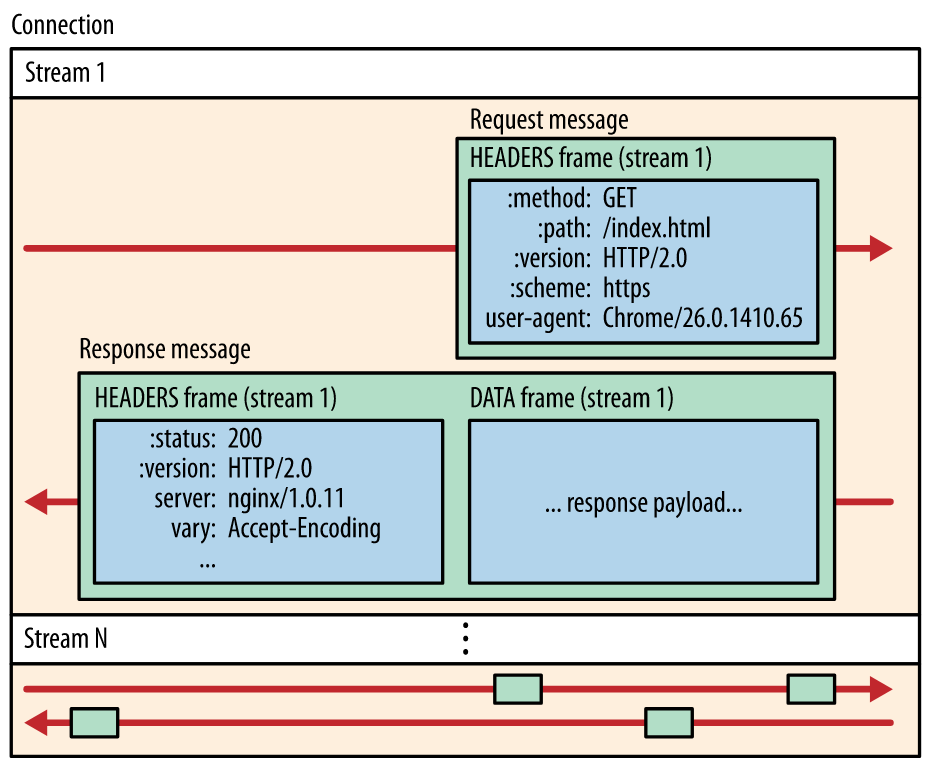
2.2 头部字段压缩
TODO
3. 一些实践的代码用例
3.1 Python Client
gRPC的错误响应(如Not Found,Internal Server Error等)通常会以异常的形式抛出,所以,Python Client必须要对gRPC的相关方法进行进一步的封装,例如重试机制或者是进行其它行为。
最为常见的异常就是_Rendezvous,该异常为RpcError的一个子类,通常来说,只需要捕获该异常即可。
import time
from grpc import StatusCode, RpcError
# define retry times with different situation
MAX_RETRIES_BY_CODE = {
StatusCode.INTERNAL: 1,
StatusCode.ABORTED: 3,
StatusCode.UNAVAILABLE: 5,
StatusCode.DEADLINE_EXCEEDED: 5
}
# define MIN and MAX sleeping seconds
MIN_SLEEPING = 0.015625
MAX_SLEEPING = 1.0
class RetriesExceeded(Exception):
"""docstring for RetriesExceeded"""
pass
def retry(f):
def wraps(*args, **kwargs):
retries = 0
while True:
try:
return f(*args, **kwargs)
except RpcError as e:
code = e.code() # 使用e.code()获取响应码
max_retries = MAX_RETRIES_BY_CODE.get(code)
if max_retries is None:
raise e
if retries > max_retries:
raise RetriesExceeded(e)
back_off = min(MIN_SLEEPING * 2 ** retries, MAX_SLEEPING)
retries += 1
time.sleep(back_off)
return wraps
3.2 Golang Server
TODO