在InnoDB存储引擎中,一个事务的执行将涉及到3个日志的数据写入: redo log,undo log以及binlog。其中redo log以及binlog主要实现事务的原子性和持久性,而undo log主要用于实现事务的隔离性。
1. redo log
redo log又称之为重做日志,主要记录了事务对数据页(Page)的物理修改。redo log由两部分组成: 一是位于内存的redo log buffer,用于对redo log进行缓冲,目的在于提升性能。另一部分则位于硬盘中,用于对redo log的持久化。
1.1 redo log buffer
redo log buffer用于优化redo log的写入性能,默认大小为16MB,最大大小为4GB。当一个事务对数据页进行修改时,首先将修改内容放置于缓冲中,而后再对其进行持久化。
1.2 redo log
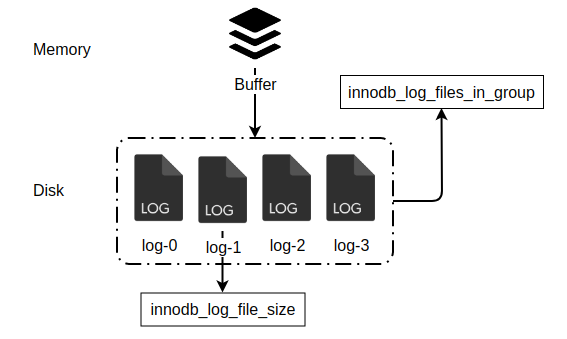
默认情况下,redo log由两个文件构成,ib_logfile0以及ib_logfile1。redo log的大小由配置文件决定,在5.7版本中,默认大小为48MB。由于其大小固定,所以数据在写入该日志文件时,将使用循环写入的方式: 首先从头开始写,写到末尾,然后再从头开始写,后面写入的内容会覆盖最初的内容,所以称之为循环写入。
redo log的文件大小设置和MySQL的负载相关,通常来说redo log应该能容纳至少一个小时的数据修改,一般innodb_log_file_size设置为1GB,innodb_log_files_in_group设置为4,总计4GB的redo log容量。重做日志大小如果设置的过大,宕机恢复时所花的时间也会越多,所以并不是越大越好。
redo log buffer中的数据将会在以下时机持久化至位于磁盘的redo log中:
- 事务提交
- 当redo log buffer有一半的空间已经被使用时
- InnoDB后台线程每秒将数据持久化至硬盘
所以,需要明确的是,当某个事务未提交(commit)时,该事务对物理数据页的修改也可能会持久化至redo log文件中。
1.3 LSN
在redo log中,还有一个非常重要的属性: LSN,Log Sequence Number,即日志序列号。接下来我们将会看到,LSN在数据恢复以及Group Commit中起到了决定性的作用。
在InnoDB存储引擎中,LSN占用8个字节,且单调递增。LSN所表示的含义包括redo log的总量,checkpoint的位置以及数据页的版本。
假设当前redo log的LSN为1000,事务T1写入了200字节的redo log,那么LSN将递增至1200。若事务T2写入了500字节的redo log,那么LSN又将变成1700。所以通过查看LSN的大小即可知道redo log的总量,单位为字节。
mysql> show engine innodb status\G;
---
LOG
---
Log sequence number 20598039739
Log flushed up to 20598039739
Pages flushed up to 20598039739
Last checkpoint at 20598039730
0 pending log flushes, 0 pending chkp writes
10 log i/o's done, 0.00 log i/o's/second
如上所示,Log sequence number表示当前的LSN,Log flushed up to表示已经刷新到redo log文件的LSN。
2. binlog
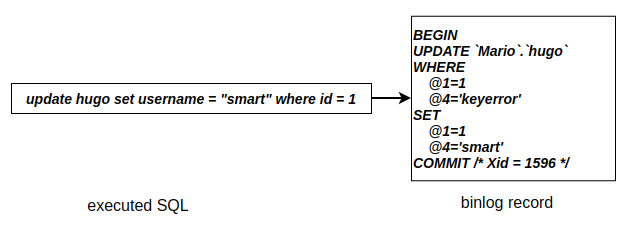
binlog为MySQL层面的逻辑日志,用于记录对哪一行数据进行了哪些修改,不管使用何种存储引擎,都会有binlog的记录。redo log则是InnoDB存储引擎所特有的日志记录,并且其中记录的是对物理数据页的修改。
关于binlog的更多内容将在后续的MySQL主从复制中描述。
3. 事务执行过程
InnoDB存储引擎在提交事务时,为了保证原子性和持久性,将会采用”两阶段”提交的方式写入redo log和binlog。
3.1 一阶段
首先,在MySQL中所有执行的SQL语句都会有一个全局递增且循环使用的query_id。当用户开启事务并执行语句后,MySQL将会把第一个语句的query_id分配给该事务,作为Xid的值。
当用户执行COMMIT提交事务时,将redo log buffer的内容调用write()系统调用写入内核缓冲区,并调用fsync()系统调用确保数据写入至硬盘(至少是硬盘的缓冲区),更新状态为prepare。
3.2 二阶段
将产生的binlog调用write()系统调用写入内核缓冲区,并调用fsync()系统调用将数据持久化至硬盘,写入成功后事务即可被提交,并更新状态为commit。

当数据成功地写入到binlog以后,即可返回给用户事务提交成功。由于数据写入.ibd文件需要随机读写,所以将会由其它线程异步写入,以提高事务执行的效率。
现在来看两阶段提交在数据库Crash的情况:
- binlog有记录,但redo log状态为prepare: 此时表示在写入binlog数据库崩溃,需要根据binlog进行数据恢复
- binlog有记录,redo log状态为commit: 事务正常提交,无需恢复
- binlog无记录,redo log状态为prepare: 事务执行一半时崩溃,无需恢复
- binlog无记录,redo log状态为commit: 在binlog持久化时崩溃,事务直接回滚
可以看到,通过上述的两阶段提交方式能够保证不会产生脏事务,并且已成功提交的事务也能够在MySQL崩溃后重启恢复。
当redo log和binlog均正确的写入数据以后,就可以返回OK给用户了。至于何时将用户的修改持久化至.ibd文件中,由MySQL后台线程决定。
基于redo log和binlog的WAL(Write-Ahead Log)机制可以保证数据的原子性以及持久性,并且由于日志是顺序读写,所以事务的执行速度会快很多。
4. Group Commit
从上图模型可以看到,每一个事务的提交,都会伴随着两次write()以及fsync()系统调用。对于Write()调用来说,仅仅只是将用户缓冲区的内容写入至内核缓冲区中,虽然会有用户态与内核态的切换,但是仍然要比fsync()要快。
如果采用上述模型实现事务的话,如果有两万个并发事务执行,那么磁盘的IO负载将会达到四万,并且事务的执行效率将会非常之差。
为了解决事务执行效率问题,MySQL引入了组提交(Group Commit)技术: 在事务提交时,尽可能多地向文件中写入数据。

如上图所示,共有3个事务并行执行,其中trx:1事务准备提交。按照之前的模型,将trx:1的redo log写入至磁盘中,并将binlog写入至磁盘中。
而在Group Commit中,当trx:1准备提交时,将会刷新最大的LSN之前未刷新的所有redo log。在该示例中,trx:1准备刷新时,则会将LSN为1600之前的所有redo log一齐刷新至磁盘。原来需要6次系统调用,现在只需要2次。
为了能够让redo log在每次写入时尽可能多的写入,MySQL将redo log调用fsync()的时机延迟,延迟至binlog调用write()之后:

这样一来,binlog也能够组提交了,能够有效地减少IOPS的消耗。
MySQL额外的提供了两个延迟参数来提高binlog的组提交效率:
# 表示延迟多少微秒后才调用binlog的fsync()
binlog_group_commit_sync_delay
# 表示累积了多少个binlog才调用binlog的fsync()
binlog_group_commit_sync_no_delay_count
这两个参数为”或”关系,即只要满足一个条件,就会调用fsync()。当磁盘IO出现性能瓶颈时,可根据实际负载来设置该值,从而降低磁盘IO负载,代价是会增加事务的响应时间。