MySQL的异步复制算的上是一种典型的单领导者复制模式,就复制本身而已并无特殊之处。但是复制的细节,例如binlog的格式选取,从节点如何在保证数据准确的情况下进行并行复制,MySQL的实现方案总是能令人眼前一亮。
1. binlog
在经典的复制模型下,主节点和从节点的数据复制都是通过日志的传输进行的。例如Redis主从复制,复制的是appendonly.aof文件中的逻辑操作记录。又如Raft一致性算法,复制的是作为”日志项”的数据记录,LogEntry。而在MySQL中,则是使用binlog作为主节点和从节点的数据复制依据。
实际上,如果观察大多数数据库应用的话,会发现它们都会有逻辑日志这一概念,其中记录了对数据的逻辑增删改。一方面用于数据库在宕机时的数据恢复(Redis、MySQL),另一方面则用于主从复制之中。
1.1 binlog记录了哪些内容?
有非常多的方式来查看binlog中的逻辑日志,一种是在MySQL-Client中查看,另一种则是直接查看位于硬盘中的binlog文件。前者其实也是读取位于硬盘中的binlog文件,只不过会对文件内容进行解析,并增加binlog内容的可读性。而后者则能够获取到更多的信息。
- MySQL-Client
mysql> show binary logs;
mysql> show binlog events in 'mysql-bin.000193';
所得到的结果如下所示:
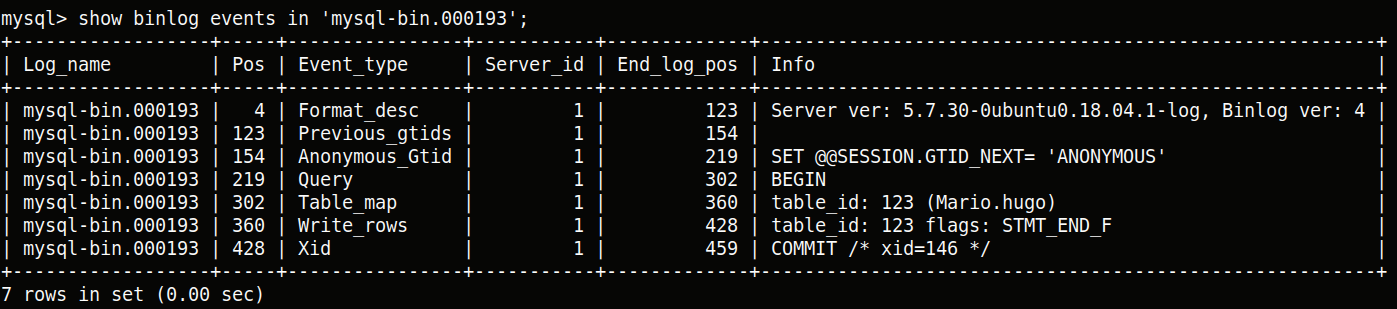
其中Pos表示该逻辑日志的起始位置,End_log_pos表示该逻辑日志的结束位置。Event_type表示事件名称,Server_id则是由用户配置的当前MySQL实例的集群ID,Info中记录了较为简短的逻辑事件。在起始位置为219的地方,实际上执行了一条insert语句,但是Info列中并没有给出详细信息。
- mysqlbinlog
smartkeyerror@Zero:~$ mysqlbinlog -vv mysql-bin.000193
得到的输出结果如下:
BEGIN
/*!*/;
# at 302
# 中间省去一些注释内容
/*!*/;
### INSERT INTO `Mario`.`hugo`
### SET
### @1=7 /* INT meta=0 nullable=0 is_null=0 */
### @2='2020-06-02 14:32:02' /* DATETIME(0) meta=0 nullable=0 is_null=0 */
### @3='2020-06-02 14:54:07' /* DATETIME(0) meta=0 nullable=0 is_null=0 */
### @4='nami' /* VARSTRING(256) meta=256 nullable=0 is_null=0 */
### @5='16399553366' /* VARSTRING(44) meta=44 nullable=0 is_null=0 */
# at 428
#200602 14:54:07 server id 1 end_log_pos 459 CRC32 0x27a642a3 Xid = 146
COMMIT/*!*/;
# at 459
其输出内容要比show binlog events更加完整,除了事务的起始位置和结束位置以外,还包括事务的执行时间,以及完整的数据记录、相关字段的注释。所以,当需要查看binlog的详细内容时,尽量使用mysqlbinlog命令行工具。
1.2 binlog日志格式
MySQL一共提供了3种binlog日志格式,分别是STATEMENT,ROW以及MIXED。
- 查看当前binlog_format格式
mysql> show variables like "binlog_format";
- 在线修改binlog_format格式
mysql> set global binlog_format = STATEMENT;
mysql> set global binlog_format = ROW;
mysql> set global binlog_format = MIXED;
STATEMENT日志格式仅记录用户所执行的SQL语句,用户执行什么,binlog就记录什么,属于最节省硬盘空间的一种日志格式。

但是,无论是出于数据恢复的考虑,还是出于主从复制的目的,都不应该将binlog格式设置为STATEMENT。其原因在于STATEMENT格式的日志依赖于执行SQL时的上下文,例如日期函数,rand函数,不同的执行环境下得到的结果可能并不相同,从而导致主从的数据不一致。而对于数据恢复而言,当然是数据越详细越完整更好。
ROW日志格式将记录完整的数据变更记录,每一条insert语句都会记录每个字段的插入值,对于update语句,则会记录数据更新前和更新后的完整数据(binlog_row_image值为FULL)。其缺点就是占用硬盘空间较多,假设一条update语句更新了10万条数据,那么在ROW格式的binlog中则同样会记录10万条数据。
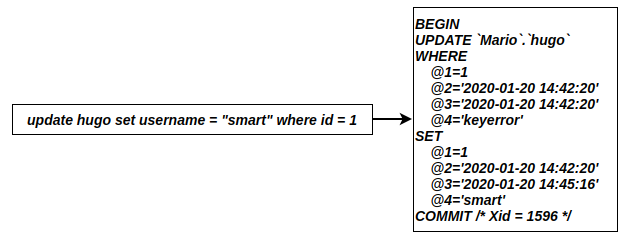
MIXED日志格式结合了STATEMENT和ROW日志格式,当MySQL认为当前SQL语句不会引起歧义,即不会导致主从不一致时,将使用STATEMENT格式记录,反之使用ROW格式进行记录。节省了一部分的硬盘使用空间,同时又能够保证数据在主从之间的一致性。
在实际应用中,应将binlog日志格式最低设置为MIXED,如果磁盘空间确实比较紧张的话。否则,就应该将binlog日志格式设置为ROW,该格式对于数据的误删操作恢复有非常大的帮助。
1.3 binlog_row_image
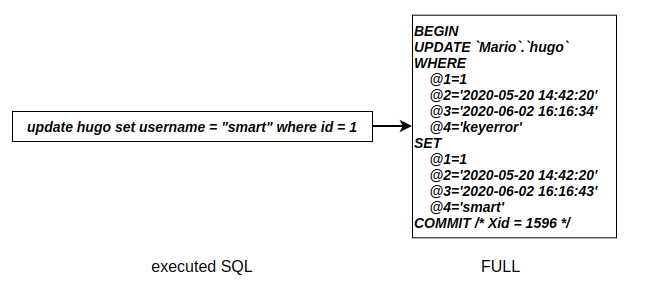
当binlog_format的值为ROW时,还有一个控制binlog日志记录的参数: binlog_row_image。该参数同样有3个可选项: FULL,MINIMAL以及NOBLOB。该参数控制了ROW格式的binlog日志在写入数据时是否写入完整数据。
FULL将会记录数据修改前后的完整字段,包括未被修改的字段:
MINIMAL则采用最小记录原则,仅记录修改行的关键定位信息(例如主键或者唯一键),以及最终被修改的字段的修改值,而不会记录那些没有被修改的字段:
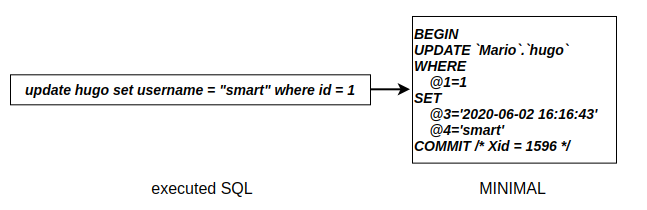
NOBLOB和FULL非常类似,会记录完整的字段修改前后数据,只不过不会记录未被修改的、且字段类型为BLOG或TEXT的数据,实际应用较少。
在主从复制中,如果主库网络带宽或者从库网络带宽无法立即升级,并且同步的日志量较大时,可临时的将binlog_row_image参数由FULL更改为MINIMAL,减少一部分的网络带宽使用。
2. 异步复制模型
对于异步复制模型而言,从原理上来说,只需要将逻辑日志不断地发送给所有的从节点,让从节点重新执行逻辑日志的内容即可,也不需要关心从节点是否接收成功并且执行成功。
MySQL的异步复制模型也确实如此。主节点开启binlog dump线程,用于锁定地读取binlog内容,并通过TCP长连接发送给从节点。而对于从节点来说,将会开启一个slave I/O线程,用于和主节点建立TCP连接,以及接收主节点发送的binlog逻辑日志,并将接收到的数据写入自身的中继日志(relay log)文件中。另外的一个线程,即slave SQL线程,将不断地读取中继日志数据,并执行其中的逻辑SQL语句。

2.1 为什么需要relay log(中继日志)?
从节点在接收到主节点发送的binlog日志之后,并没有直接执行,而是存储在relay log中,由另外一个线程读取该文件的数据并执行。那么MySQL为什么要使用这种会降低复制效率的设计?
个人认为原因有两点,一方面relay log可以作为日志同步的缓冲区。主节点发送日志的速度可能要大于从节点执行日志的速度,此时就需要一个缓冲区来弥补两者之间的速度差,避免主节点发送的binlog被阻塞在socket缓冲区中。
另外一个作用就是利于故障时的问题排查。relay log的结构与binlog非常相似,通过在从节点持久化一份主节点发送的日志,那么在出现故障时,可查看该文件的内容来大致地判断是主节点出了问题,还是从节点出了问题。
这种数据冗余的设计在业务系统设计中其实也非常实用,相较于直接执行外部发送的数据,采用”生产者-消费者”模型将会有更好的健壮性: 在微服务中,”数据同步”是一件极易出错,且令人无比蛋疼的苦差事。当保留源数据,并在源数据的基础之上开展业务的话,能避免许多麻烦。
3. 并行复制

在主节点中,由于存在各种各样的Lock, 例如共享锁,排它锁,意向锁等等,使得事务可以并发执行,而无需担心数据不一致的问题。但是,在从节点如果想要并发执行binlog中的内容,并不是一件容易的事情,其原因在于事务和事务之间并不是完全独立存在的,而是存在依赖性。
如上图所示,从节点Execute中继日志的内容将会成为主从复制最后的延迟点,同时,也可能是最大的延迟点: 因为binlog dump线程以及slave I/O线程均是对文件的顺序读取和写入,而slave SQL线程在执行语句时,则没有那么简单。
3.1 并行复制所面对的问题
假设现在有3个事务并发执行,且修改的是同一行数据,并且事务提交的顺序为TRX-1,TRX-2,TRX-3,则数据的新旧程度为: TRX-3 > TRX-2 > TRX-1。
当从节点SQL执行线程读取中继日志时,并不知道这3个事务是修改的同一条数据,如果只是简单地将这3个事务分配给3个Worker执行的话,完全有可能发生旧数据覆盖新数据的情况,即TRX-1最后被执行,TRX-3的最新更新将会丢失,导致从节点和主节点的数据不一致。
3.2 基于table的并行复制
如果两个事务是对不同的表进行操作,那么这两个事务即可并行执行。处理方式也非常简单,对表名称进行哈希,并对结果进行worker数量的取模,将该事务分发至对应的worker即可。
但是,如果事务同时对多张表进行了修改的话,上述模型就会出现问题: 该事务应该分配给哪个worker? 所以,还需要记录每个线程中有哪些事务正在执行或者排队,操作的是哪些表。对于线程私有变量,可以使用ThreadLocal来实现,外部也可方便的获取线程中的私有内容。
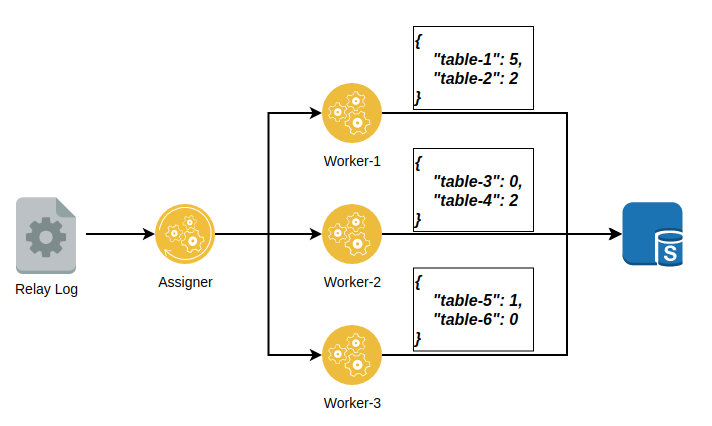
如上图所示,Assigner线程读取relay log中的内容,并对数据进行解析,决定将该事物分配给哪个worker执行。worker线程则是事务的执行线程,并且使用哈希表记录下当前线程队列中有多少个事务正在修改哪些表。其中key为表名称,value为队列中有多少事务修改该表。
当Assigner读取到只修改table-1的事务时,遍历所有worker的哈希表,判断是否有其它worker正在执行关于table-1的事务,发现只有worker-1存在,那么将会直接将其分发至worker-1线程,并将事务追加至该worker的队列中,以此保证对同一个表的操作串行执行。
当Assigner读取到同时修改table-1和table-3的事务时,首先根据解析规则获取到这两个表应该被分配的worker,然后取出两个队列中正在对table-1和table-3所修改的事务数量。发现worker-1存在对table-1的事务,而worker-2对table-3的修改事务数量为0,那么Assigner将会将该事务分配给worker-1。
当Assigner读取到同时修改table-1和table-4的事务时,发现worker-1和worker-2都存在对两个表的修改,那么Assigner将会等待,等待worker-1对table-1的修改事务数量为0,或者是worker-2对table-4的修改事务数量为0。
在大多数情况下基于表的并行复制策略能够快速地执行,但是,如果遇到热点表的话,该热点表仍然是串行复制,同样会出现效率问题。
3.3 基于行的并行复制
既然基于表的并行复制会有热点表的问题,那么基于行的并行复制总没有热点表的问题了吧? 并且同一条数据的修改频率并不会特别高。基于行的并行复制虽然能够有着更快的执行效率,但是同样地带来的更多的内存开销和CPU计算开销。
在基于行的并行复制中,至少需要记录下所有正在被修改或者是已经在队列中的行数据,那么显而易见的,worker线程中的哈希表将会有存在大量的数据。所以综合来看,基于行的并行复制并不是一个好的选择,甚至可以说是一个比较差的选择。
但是,MySQL针对基于行的复制进行了优化,将判断两个事务是否存在”冲突”(即是否更新了同一行)由从节点转移至主节点。MySQL会记录下更新的每一行的哈希值,组成一个集合。为了能够唯一标识同一行,哈希值通常由”库名+表名+唯一索引名+唯一索引值”计算得到,而唯一索引通常是主键。
如果两个事务没有同时更新同一条数据,那么两个事务的集合就不存在交集,它们是可以并行执行的。并且该哈希值集合是在主节点写入binlog时即计算好的,不需要从节点再次解析binlog event,节省了从节点的一部分计算资源。
3.4 基于Group Commit的并行复制
InnoDB存储引擎是通过redo log + binlog来实现事务的原子性以及持久性的,为了保证数据的一致性,两个日志的数据写入通过”两阶段提交”完成,并且使用组提交(Group Commit)来提高事务的并发效率。

当未使用组提交时,当trx:1提交,仅将该事务的数据持久化至redo log以及binlog中,当有两万个事务并发执行时,将需要执行四万次fsync系统调用。
当使用组提交时,当trx:1提交,redo log buffer中可能存在多个事务的物理页修改,那么此时trx:1将会作为Leader,将当前最大的LSN redo log持久化至磁盘,以减少fsync的系统调用次数。并且,为了尽可能多地在一次写入中写入更多的数据,InnoDB还会推迟redo log的fsync过程。

更具体的上下文请参考文章: InnoDB如何保证事务的原子性与持久性
假设多个事务能够同时进入prepare阶段,那么这些事务一定能够并行执行。 接下来分析一下这句话的正确性:
- 事务A和事务B并发执行,准备修改同一条数据。由于X Lock的存在,当一个事务修改数据时,另一个事务将会被阻塞,等待前一个事务提交。
- 假设事务A首先获得了X Lock,成功修改了数据并提交了事务。而此时,事务B仍然处于运行中,在获取到数据的X Lock之后才开始执行自己的修改。
所以,只要是能够同时进入prepare的阶段,事务一定是经过了锁冲突的检验,一定能够在从库并行执行。
如此一来,当redo log在使用最大的LSN持久化至磁盘时,使用一个commit_id对该事务进行标记。下次的redo log持久化将commit_id自增。从库在并行执行binlog event是,只要是相同的commit_id,就使其并发执行。
3.5 MySQL提供的并行复制配置项
MySQL一共提供了三种并行复制策略,由参数binlog_transaction_dependency_tracking控制(MySQL版本大于5.7.22)。
- COMMIT_ORDER: 利用Group Commit机制进行并行执行。
- WRITESET: 基于行的并行执行。
- WRITESET_SESSION: 建立在WRITESET策略之上,只不过多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序。
其中COMMIT_ORDER为默认策略,当使用该策略时,可以调整binlog_group_commit_sync_delay以及binlog_group_commit_sync_no_delay_count来使得主节点更慢的提交,使从节点更快的执行事务。
当主节点事务执行的并发度较高时,可以选择COMMIT_ORDER策略。当主节点事务执行并发度并不高,并且趋近于单线程或者双线程时,可选择WRITESET策略。
4. 主从延迟来源
4.1 从节点硬件资源不足
有时候我们会认为从库只负责读请求,而不处理客户端的写请求,所以从库的内存、硬盘以及CPU都可以使用较低配置。但事实上,从库需要处理的数据写入并不会比主库要少,同时还要处理比主库更多的读请求。因此,从库的硬件资源应该至少和主库相同,甚至可以高于从库。
通过top或者是htop可以很清晰的得到从节点的内存以及CPU使用率,使用iostat查看从节点的磁盘I/O活动情况。iostat有几个非常关键的指标:
smartkeyerror@Zero:~$ iostat -m
Linux 4.15.0-101-generic (Zero) 2020年06月04日 _x86_64_ (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
4.93 0.01 2.58 0.59 0.00 91.88
其中%iowait表示CPU等待输入输出完成时间的百分比,%idle表示CPU空闲百分比。如果%iowait的值较高,说明硬盘存在I/O瓶颈; 如果%idle持续较低,说明系统的CPU处理能力较弱,此时应处理CPU资源。
4.2 主节点大事务与从节点长事务
大事务是指更新了较多数据行的事务,当从节点重放大事务的binlog event时,不管是使用COMMIT_ORDER还是WRITESET并行复制策略,后续操作均需要等待该事务的执行,事务执行所需要的执行时间越久,主从延迟就会越高。所以,尽量地将大事务拆分成多个小事务执行。
从节点长事务同样也可能导致主从延迟的产生。例如,当从库开启了一个长事务:
BEGIN;
SELECT * FROM hugo WHERE username = "smart";
执行完SELECT语句之后因为种种原因长时间未提交事务,那么此时若主库对该表进行了DDL操作,即使hugo表只有几行数据,也会长时间的阻塞: 因为此时DDL操作无法获取到hugo表的意向排它锁(IX)。
如果主表的DDL操作在白天进行,并且恰好存在对该表的某一个长事务的话,即使不是高峰期也会带来非常大的主从延迟。
4.3 从节点未开启并行复制
从节点的并行执行worker数量由slave_parallel_workers参数决定,最大值为1024,通常将其设置为CPU核心数的一半。