Java中的I/O系统相较于Python要复杂许多, 不管是从设计上还是实现上。 这一块儿的内容也是我在学习Java时遇到的最大的困难(并发包都比这个好理解), 经过了持(san)之(tian)以(da)恒(yu)的学习之后, 算是对Java I/O系统有一个基本的认识和理解。
1. Python语言下的I/O系统
作为一个PythonCoder, 首先当然是要对Python I/O系统做一个详细的梳理, 在比较中理解和提高。 在Python中, 所有的文件操作, 不管是读还是写, 都以打开一个文件起手, 同时为了更好的管理文件资源, 可以使用上下文管理器with语句:
# 读文件
with open("hello.txt", "rt") as f:
data = f.read()
# 写文件(覆盖写)
with open("hello.txt", "wt") as f:
f.write("hello\nworld\n!")
不得不说, 是真的简单…那么我们就需要彻底的理解Python对文件的操作, 越是简单的内容, 越是不能掉以轻心。 最佳的参考文献就是builts.py中的文档注释。
首先来看open函数中的模式选择, 一共有8种操作模式, 其中U模式并不建议使用:
| 字符 | 含义 | 字符 | 含义 |
|---|---|---|---|
| r | 打开一个文件并进行读取 | w | 打开一个文件并进行写入(覆盖原有文件内容) |
| x | 创建一个新的文件, 并将其打开准备写入 | a | 打开一个文件并以追加的方式进行写入 |
| b | 以二进制的格式打开文件 | t | 以文本的格式打开文件 |
| + | 打开一个文件并进行更新, 可读可写 |
文档描述的非常清楚, 举几个非常常见的例子: rb, 以二进制的方式读取文件, 在读取文件时将会得到bytes类型; wt, 以文本的方式对文件进行清空写入, 不管写不写内容, 文件内容在调用open函数时就直接被清空; 如果以ab模式写入字符类型, 将会抛出异常, 如果想要已字节模式写入中文, 需要对字符进行encode("utf-8")操作, 将其转换为字节。
with open("hello.txt", "ab") as f:
f.write("你好".encode("utf-8"))
Emoji既可以以字符写入, 也可以以byts写入, 读取的话进行一个编码的转换即可:
with open("hello.txt", "ab") as f:
# 以bytes模式打开, 那么需要写入bytes
f.write("😍 😱".encode("utf-8"))
with open("hello.txt", "rb") as f:
# 得到的data为bytes
data = f.read()
# 打印字符串需要对其进行解码
print(data.decode("utf-8"))
在文档的末尾有这样一段话: open方法将会返回一个file对象, 当我们使用t模式打开一个文件时, 将会返回TextIOWrapper对象; 当使用b模式, 并且读文件时, 返回BufferedReader对象, 写文件时返回BufferedWriter对象; 当使用+模式时, 将会返回一个BufferedRandom对象。
不管是以什么样的方式去读取或者写入文件, buffer对象是跑不掉的。 之所以有buffer存在, 是因为内存和磁盘之间的读写速度差距过大, 添加buffer可以调节两者之间的速度差, 对I/O操作进行优化。 在文档中也说明了每一种模式下的buffer大小。
在Ubuntu下进行测试时, 使用rb模式buffer大小为4096, 使用rt模式buffer大小为8192。 之所以是4096, 一方面是因为在ext4磁盘文件格式下, 其默认的block size即为4096, 另一方面当超过4096时, 其效率并没有显著的提高(具体的测试数据在unix环境高级编程有给出)。 在Python中, 使用buffer去装填数据的过程由语言底层帮我们完成, 而在Java中, 这个过程由我们自己完成。
基本上这些就是Python中对文件的读写操作了, 可以看到语言将一些细节封装到了底层, 使用者可以不用关心这些细节, 专注于自己的业务场景。 但是在Java语言中, I/O就没有那么简单了。
2. File类
在Python中, 可以直接在open方法返回的file对象上对文件的内容进行读取和写入, 但是在Java中, File类仅表示一个文件对象, 或者说是对系统磁盘文件的操作, 包括创建一个空文件, 查看文件的创建日期, 大小以及权限等。
常用的构造器:
File(String path)
File(File parent, String child)
File(String parent, String child)
归根结底就是需要传入一个文件的路径, 该路径可以使用字符串表示, 也可以将路径拆分成2个字符串或者是一个文件对象和一个字符串。 那么创建一个文件就有了很多种写法:
public class CreateFileTest {
public static void main(String[] args) throws IOException {
File file = new File("/home/smartkeyerror/JavaProjects/LearningJava/hello.txt");
boolean isCreated = file.createNewFile();
System.out.println(isCreated);
File file1 = new File("/home/smartkeyerror/JavaProjects/LearningJava", "hello1.txt");
boolean isCreated1 = file1.createNewFile();
System.out.println(isCreated1);
File file2 = new File(new File("."), "hello2.txt");
boolean isCreated2 = file2.createNewFile();
System.out.println(isCreated2);
}
}
并不是很复杂, 此外File类还提供了mkdir以及mkdirs方法来创建目录, 其中mkdir如果在文件路径中有文件并不存在, 则会抛出异常; 而mkdirs则会帮我们创建该路径下所有的文件目录, 如果该目录在磁盘中不存在的话。
list方法将会返回路径下所有的文件和目录的名称所形成的字符数组, listFiles将会返回目录下所有的文件对象:
File fileNew = new File(".");
File[] files = fileNew.listFiles();
for (File file3 : files) {
System.out.println(file3.getName()); // 获取文件或目录名称
System.out.println(file3.isDirectory()); // 判断是否为目录
System.out.println(file3.isFile()); // 判断是否为文件
}
比较值得一提的就是文件查找时策略模式的应用: 当我们想要找到目录中所有以.txt结尾的文件时, 固然可以使用循环遍历在进行判断, 同时也可以使用FilenameFilter这个”策略”对象来实现:
File file = new File(".");
String[] files = file.list(new FilenameFilter() {
public boolean accept(File dir, String name) {
return name.endsWith(".txt");
}
});
我们可以看一下list方法的源码:
public String[] list(FilenameFilter filter) {
String names[] = list();
/** 当filter为null时直接返回names数组 */
List<String> v = new ArrayList<>();
for (int i = 0 ; i < names.length ; i++) {
if (filter.accept(this, names[i])) {
v.add(names[i]);
}
}
return v.toArray(new String[v.size()]);
}
可以看到具体的实现还是一个循环遍历, 但是这个循环遍历交给了JDK去处理, 我们只需要定义一个filter对象并赋予其相关规则即可, 简化开发人员代码编写的数量(当然, 按行数算工资的当我没说)。
3. Stream类
当我们使用new File创建了一个文件对象, 紧随其后的就是读取或者向文件写入内容, 那么此时就有了2种选择:以字符的方法读取/写入, 以字节的方式进行读取/写入。 基于此, Java才会有4个抽象类, 来对应不同模式的读和写。
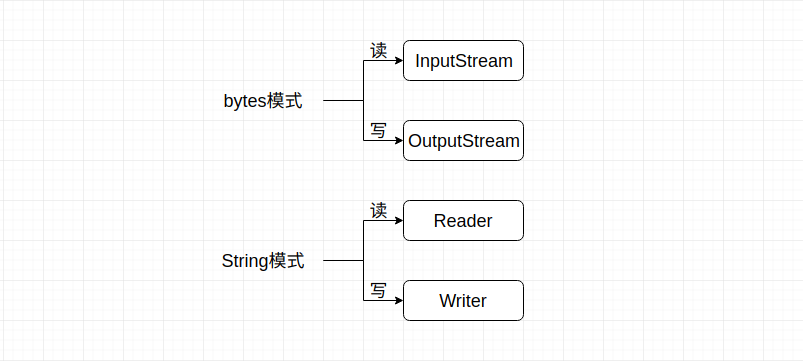
我们可以使用不同的组合来实现不同模式的读取和写入, 例如使用InputStream读取bytes, 然后使用Writer将bytes转换成字符之后写入, 或者以相反的方式来对文件内容进行操作。 在涉及具体的实现类之前, 首先要理解读文件和写文件的基本模式:
# 读/写数据的逻辑:
open a stream
while more information
read/write information
close stream
文件操作在开发中最为常见, 所以就以FileInputStream和OutputStream为例, 进行梳理。 首先来看read方法, 最完整的参数列表如下:
public int read(byte b[], int off, int len) throws IOException
其中的b[]即为一个buffer数组, 用于接受文件数据; off为读取文件时的偏移量, 即从哪个地方开始读取; len表示每一次的读取最多读多少数据, 该参数的最大值不能超过buffer数组的大小减去偏移量的大小, 如果偏移量为0, 那么该值最大为数组大小。 通常来讲4096就好, 参考第一小节的解释。
该函数将会返回每次读到的bytes数量, 如果说已经读到了EOF, 即文件末尾, 将会返回-1, 该值会作为我们判断文件是否读完的标志。
public class FileReadTest {
public static void main(String[] args) throws IOException {
/* 创建文件对象 */
File file = new File(".", "hello.txt");
/* 创建buffer数组, 大小为4096 */
byte[] buffer = new byte[4096];
/* 传入文件文对象, 打开一个流 */
FileInputStream fileInputStream = new FileInputStream(file);
int length = 0;
/* 当文件没有读完时, 将所读取到的数据转换成为字符并向控制台输出 */
while ((length = fileInputStream.read(buffer, 0, 4096)) != -1) {
String string = new String(buffer, 0, length);
System.out.println(string);
}
/* 最后需要关闭这个流 */
fileInputStream.close();
}
}
写文件的话要稍微简单一些, 流程与读文件基本类似:
public class FileOutputTest {
public static void main(String[] args) throws IOException {
FileOutputStream fileOutputStream = new FileOutputStream("hello.txt");
StringBuilder buffer = new StringBuilder();
for (int i = 0; i < 100; i++) {
buffer.append("hello World~ \n");
}
fileOutputStream.write(buffer.toString().getBytes());
fileOutputStream.close();
}
}
针对于输入的来源, 还有ByteArrayInputStream, 将字节数组作为输入源; StringBufferInputStream, 将String对象作为输入源; SequenceInputStream将多个输入流合并成一个输入流。 此外还有FilterInputStream这个抽象类作为装饰者对输入流进行装饰, 具体的内容在后面梳理。
有输入那么自然就会有输出, 除了FileOutputStream向文件中输出以外, 还有ByteArrayOutputStream, 在内存中创建一个缓冲区, 数据写入该缓冲区; PipedOutputStream, 实现管道化的概念。 以及FilterOutputStream对输出流进行装饰。
4. RandomAccessFile类
RandomAccessFile提供了与Python非常类似的文件读写方式, 但是前提是我们对文件的结构有一个清晰的了解, 例如要记录数据的大小以及位置。
首先来看构造参数, 第一个参数可以是String或者是File对象, 表示文件路径; 第二个参数表示模式的选择, 一共有4种模式:
| 字符 | 含义 | 字符 | 含义 |
|---|---|---|---|
| r | 只读模式打开文件 | rw | 以读/写的方式打开文件, 若文件不存在则尝试创建 |
| rws | 以读/写的方式打开文件, 并且内容或源数据更新时将数据立即同步到磁盘中 | ||
| rwd | 与rws非常类似, 内容数据更新时将数据立即同步到磁盘中 |
RandomAccessFile包含了一个指针对象,用于标识当前流的读写位置, 并为该对象提供了get和set方法, 只不过名称是getFilePoint和seek。
public class RandomAccessFileDemo {
public static void main(String[] args) throws IOException {
RandomAccessFile file = new RandomAccessFile("hello.txt", "rw");
byte[] buffer = new byte[4096];
int length = 0;
int count = 0;
while ((length = file.read(buffer, 0, buffer.length)) != -1) {
System.out.println(new String(buffer, 0, length));
/* 记录已经读取的字节数 */
count += length;
}
/* 跳过已读取字节数个字节 */
file.skipBytes(count);
/* 相当于文件末尾追加数据 */
file.write("append".getBytes());
file.close();
}
}
没有使用任何的InputStream以及OutputStream, 就对同一个文件进行了读写操作。 上面演示的为向文件末尾进行追加, 使用了自定义的count来记录已读的数据, 实际上可以直接使用:
file.seek(file.length());
file.write("\nappend".getBytes());
file.length将会返回当前文件的字节大小, 我们直接使用seek方法将指针定位到末尾, 进行追加写入即可。
5. Filter装饰类
Filter装饰类是对”流”进行装饰的类, 同样分为字节装饰和字符装饰, 并且根据输入/输出的不同也存在着不同的实现结构。
首先来看字节的相关装饰类:
| 类 | 功能 |
|---|---|
| DataInputStream, DataOutputStream | 允许读取/写入Java基本类型数据 |
| BufferedInputStream, BufferedOutputStream | 使用缓冲区的方式读取/写入数据, 减少I/O次数 |
| PushbackInputStream | 主要由编译器使用, 业务开发基本不会用到 |
| PrintStream | 属于输出装饰, 用于格式化的输出 |
字符相关装饰类:
| 类 | 功能 |
|---|---|
| BufferedReader, BufferedWriter | 以缓冲区的方式进行读写, 减少I/O次数 |
| LineNumberReader | 可以使用readLine方法逐行读取 |
| PrintWriter | 格式化输出 |
| PushbackReader | 通过缓存机制, 进行预读 |
| InputStreamReader, OutputStreamWriter | 字节流和字符流的相互转换 |
public class SimpleDemo {
public static void main(String[] args) throws IOException {
FileInputStream in = new FileInputStream("hello.txt");
BufferedInputStream bufferedInputStream = new BufferedInputStream(in);
InputStreamReader inputStreamReader = new InputStreamReader(bufferedInputStream);
/* 首先我们先将其读出来, 此时已经是字符流 */
char[] chunk = new char[4096];
int data = inputStreamReader.read(chunk);
/* 新建输出流 */
FileWriter fileWriter = new FileWriter("hello1.txt");
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
while (data != -1) {
System.out.println(new String(chunk, 0, data));
bufferedWriter.write(chunk, 0, data);
/* 写入数据 */
data = inputStreamReader.read(chunk);
}
/* 关闭资源 */
inputStreamReader.close();
bufferedWriter.close();
}
}
5.1 装饰模式
在看Java的装饰模式之前, 首先来看Python中的装饰器:
def wrapper_func(func):
@wraps(func)
def inner_func(*args, **kwargs):
start = time.time()
func()
print("function cost time: {}".format((time.time() - start)))
return inner_func
wrapper_func
def do_something(*args, **kwargs):
"""
do_something useful
"""
time.sleep(1)
print("This is main function")
if __name__ == "__main__":
do_something()
print(do_something.__doc__)
没有什么很复杂的地方, @是一个语法糖, 本质上其实会调用:
do_something = wrapper_func(do_something)
在Java中的装饰模式调用方式也是这样的, 由于存在着强制类型声明, 所以在Java中实现装饰模式要稍微复杂一些。 do_something对象类型与wrapper_func函数所返回的对象类型应该一致, 那么将函数往上提一层, 就到了类这个层面, 所以说, do_something和wrapper_func必须是同一个对象。
所以就有了统一的接口, 应用类和装饰类均实现该接口, 并且在装饰类中需要注入一个应用类的实例, 并通过类似代理的方式调用应用类对象的方法以及自己实现的方法。 下面就写一个最简单的装饰模式:
interface Work {
void work();
}
class HomeWork implements Work {
@Override
public void work() { System.out.println("做家庭作业"); }
}
class Decorator implements Work {
private final Work work;
Decorator(Work work) { this.work = work; }
@Override
public void work() {
work.work();
System.out.println("做其它的作业");
}
}
public class SimpleDecorator {
public static void main(String[] args) {
HomeWork homeWork = new HomeWork();
Decorator decorator = new Decorator(homeWork);
decorator.work();
}
}
在这里我将Decorator类直接做为了一个装饰类, 本来这里应该是一个抽象类, 让具体的装饰类实现继承该抽象类, 已达到更好的复用效果。 嘛, 测试嘛, 洒洒水啦~ I/O包里面所有的装饰模式都是以这样的结构来实现的, 具体的类图就不贴了。
6. NIO
在文件操作上, 我更倾向于将NIO解释为New-IO, 即新的I/O方式; 在Reactor模型中, 更倾向于将其解释为No-Blocking I/O, 即同步非阻塞I/O。
在NIO中, 不再面向”流”编程, 而是面向缓冲区编程。 NIO最重要的两个概念就是channel和buffer, 借鉴Thinking in Java中的举例, 可以将磁盘比作一个煤矿, 将通道(channel)包含煤层(数据), 缓冲区(buffer)就是运煤的卡车。 卡车从煤矿中满载而归, 煤块加工处负责将煤块从车上取出, 在这个过程中我们没有和煤矿直接打交道, 而是和卡车打交道。 这也是NIO的基本原理, 我们只能向buffer中读取或者写入数据, 再由buffer向channel读取或者写入数据。
FileInputStream inputStream = new FileInputStream("hello.txt");
/* 获取Channel对象 */
FileChannel channel = inputStream.getChannel();
/* 声明Buffer对象 */
ByteBuffer buffer = ByteBuffer.allocate(4096);
/* 将数据从channel写入至buffer中 */
channel.read(buffer);
/* 将buffer相关变量还原 */
buffer.flip();
while (buffer.hasRemaining()) {
byte b = buffer.get();
System.out.println("character: " + (char)b);
}
channel.close();
这是一个不那么严谨的demo, 因为只能读取4096个字节的数据, 但是不妨碍我们对channel和buffer的理解。 首先获取FileInputStream对象的FileChannel对象, 之所以可以这样做是因为该文件输入流已经以使用NIO的方式进行重写了, 然后我们使用ByteBuffer的静态方法声明了一个有界的缓冲区, 将数据通过channel装填至buffer中, 并对buffer进行翻转, 以及数据的读取。
6.1 buffer原理
在上面我们简单的使用buffer的方式对文件进行了读取, 在本小节中对buffer进行更深入的理解。
根据Javadoc, buffer是一个线性的有界序列, 保存着特定的基本数据类型, 除去保存的内容, 最核心的属性就是capacity, limit以及position。
capacity指定buffer的容量, 一经定义无法修改, 且该值不允许为负数; limit表示在一个buffer中, 不允许读取或写入的第一个元素的索引; position表示下一个将要读取或写入的元素的索引。 听起来非常的绕口, 以图示进行解释:

图示与上面的代码没有直接关联。
初始化: position = 0, capacity与limit值相同, 值为数组大小, 可以认为其指向最后一个元素的下一个元素
向buffer中写数据: 也就是调用channel.read(buffer), 假设写了4个元素, 那么position向后移动4位, 其余值不变
准备读取元素: 此时必须调用flip方式使得position置0, 而limit则指向原来position的位置
读取元素: 在读取元素时, position的位置会不断的向后移动, 直至移动到与limit相同的位置。 此时元素已经读取完毕, position再向后移动就没有了意义。
从上面的过程可以看出, 假设我们的buffer大小为4096, 但是文件只有20个字节的数据, 向buffer中写数据和读数据都不会造成空间和时间上的浪费, 基于此的设计使得NIO要比旧IO有更高的效率。
在有了buffer之后, 我们进行文件内容的拷贝就变得非常简单了:
public class NIOCopyFile {
public static void main(String[] args) throws IOException {
FileChannel inChannel = new FileInputStream("hello.txt").getChannel();
FileChannel outChannel = new FileOutputStream("hello1.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(4096);
while (inChannel.read(buffer) != -1) {
buffer.flip(); // 翻转buffer, 准备进行buffer的读操作
outChannel.write(buffer);
buffer.clear(); // 将buffer的position, limit置为最初状态, 以便接收后续数据
}
inChannel.close();
outChannel.close();
}
}
6.2 ByteBuffer源码分析
在我们敲下:ByteBuffer buffer = ByteBuffer.allocate(4096);, 中间发生了什么?
allocate是一个静态方法, 返回一个HeapByteBuffer对象实例, 里面的方法倒是没什么好说的, 比较重要的一点就是该buffer中的数组是位于堆内存中的。 那么也就意味着数据需要从堆内存拷贝到 OS拷贝空间当中, 会有一定的性能损耗。
所以, NIO还提供了一个直接缓冲区, 即DirectByteBuffer, 该buffer的行为与堆buffer基本类似, 只不过直接缓冲区将buffer的内存直接声明在了堆外, 并使用一个long变量来指向这块儿内存。
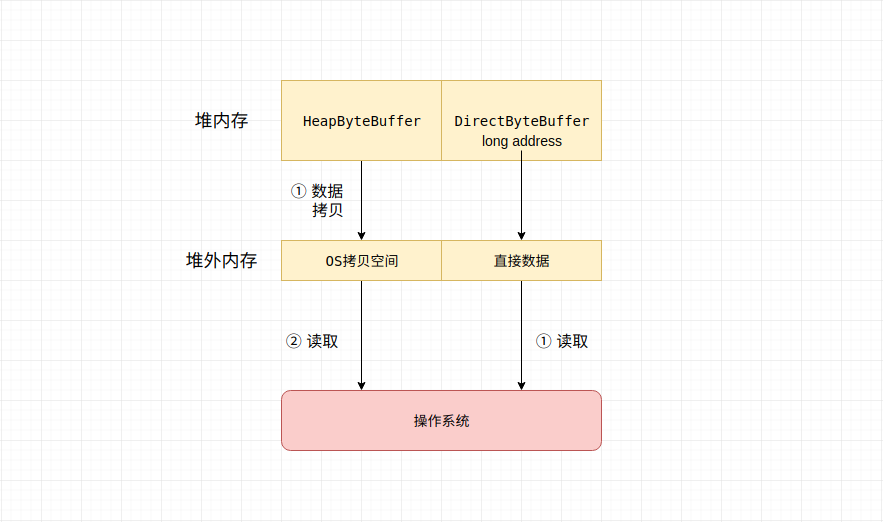
虽然看起来DirectByteBuffer能够加快数据的访问, 但是这与操作系统的类型直接相关, 所以在使用直接缓冲区时, 需要对其进行基本的性能测试, 保证确实要比堆缓冲区更快。
7. 小结
Java的I/O系统看起来设计的非常复杂, 但是对其抽丝剥茧, 一层一层的将其展开, 理解起来也并不会特别的复杂。 在本篇文章中对一些常用的类以及技术做了比较粗略的介绍和demo, 在工程实践中要比这更加的复杂, 但是万变不离其宗, 原理性的知识的确只有一少部分。 当我们理解了应用层序和操作系统之间的关系以及相关操作逻辑, 一些困扰我们的问题也就自然迎刃而解了。