在我刚接触Python这门开发语言时, 并没有想用它做Web后端开发, 而是拿来写爬虫。 第一个接触的爬虫框架就是Scrapy。 网络爬虫绕不开的一个话题就是URL去重问题。 在Scrapy原生框架下, 使用的是集合来对URL进行去重的。 集合本身采用哈希表实现, 是一种典型的以空间换时间的数据结构, 当URL数量极为庞大时, 使用这种策略的去重很有可能导致内存溢出而造成服务器宕机的问题。 此时, Bitmap走进了我的视线。
1. 什么是Bitmap
现代计算机使用二进制来作为信息存储和传输的基本单位, 由于计算机是老美发明的, 他们只需要使用A-Z这26个英文字母, 再加上一些字符, 就可以表达所有的文字内容了。 所以就有了ASCII编码, 使用8个bit(位)来表示一个byte(字节)。
例如”Hey”这个字符, 是由3个字节所组成的, 分别是’H’, ‘e’, ‘y’, 所对应的ASCII码分别是72, 101, 121。 将其转换成二进制, 分别为01001000, 01100101, 01111001。 也就是说, “Hey”这个单词, 在底层存储时, 是使用010010000110010101111001来进行存储的。
在了解了这些内容之后, 再来看如何通过Bitmap来进行URL去重。 假如对于https://smartkeyerror.com/这个URL, 我们对其进行某种编码操作, 让它变成一个数字, 例如12; 对于https://smartkeyerror.com/categories/这个URL采用同样的编码方式, 将其变为一个数字, 例如7…以此类推, 有10亿个URL, 就有10亿个数字。
在上面我们得到了两个数字, 一个是12, 一个是7, 分别代表了两个URL。 接下来构建一个以位为单位的数组, 将这两个URL所代表的数字作为数组索引, 修改其值为1, 得到的结果就是这样的:
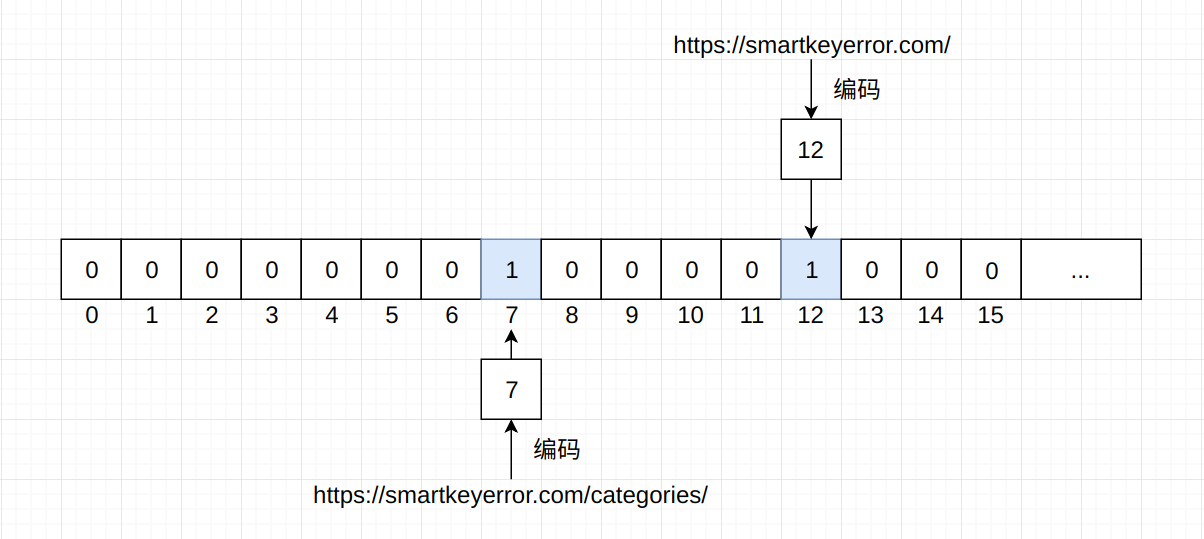
如果爬虫再次爬取了https://smartkeyerror.com/这个URL, 通过编码得到了12, 发现这个数组索引为12的元素值为1, 那么就知道这个URL已经被爬取过了, 不会再次进行爬取, 也就达到了去重的作用。
在图中, 位所组成的数组有16个元素, 即能够表示16个URL, 占用空间仅有2个字节。 如果有10亿个URL, 占用空间为 10×10^8 / 8 = 125×10^6字节, 约为125M, 对内存要求非常之低。
2. Bitmap的实现
如果是自己使用Python或者是Java来实现Bitmap这种数据结构的话, 还是比较麻烦的, 所以能够捡现成的用最为合适, 如果现成的不符合特定的需求的话, 自己实现也不迟。
Redis所实现的Bitmap接口相当的简单:
# 设置值
setbit key offset value
# 获取值
getbit key offect
Bitmap除了能够用来进行数据去重以外, 还可以做一些统计功能。 例如用户每天对网站的访问情况, 使用用户id作为Bitmap的偏移量, 如果访问了, 将其值修改为1:
setbit user_access_2019-03-10 15 1
setbit user_access_2019-03-10 25 1
setbit user_access_2019-03-10 1688 1
上面的3条命令表示在2019-03-10这天, id为15, 25, 1688的用户访问了网站。 通过使用bitcount命令可以很方便的统计出当天总访问用户是多少:
bitcount user_access_2019-03-10
并且, Redis提供的Bitmap实现支持4种运算操作, 分别是and(交集), or(并集), not(非), xor(异或), 并将结果保存至destkey中。
bitop option destkey key1 key2 .....
例如, 查看2019-03-10和2019-03-09这两天都访问了网站的用户数量:
bitop and user_access_2019-03-09_10 user_access_2019-03-09 user_access_2019-03-10
3. 利用Bitmap实现网站标签统计
这几天在拉钩上更新了自己许久未更的简历, 发现多了一个功能: 综合能力。 这一项需要我们从众多的能力标签中选出5个符合自己能力的标签, 例如沟通协调能力, 自驱动, 抗压能力等等。 自然, 我们可以用一个数组列表来对这些标签进行存储并展示, 但是在数据统计时, 就会有些麻烦了。
如果采用列表存储标签的方法来做的话, 想要统计给自己打上”自驱动”标签的用户数量是多少, 或者是哪个标签是用户作为喜爱的标签等等, 这些统计功能很难展开。
这个时候Redis实现的Bitmap就派上用场了, 假如标签有self-driven, communication-skills, work-well-under-pressure等等, 同样采用用户id作为偏移量:
setbit self-driven 15 1
setbit self-driven 2544 1
setbit communication-skills 15 1
setbit communication-skills 268 1
setbit work-well-under-pressure 125 1
统计”自驱动”标签的用户数量:
bitcount self-driven
统计最热门的标签:
bitcount self-driven
bitcount communication-skills
bitcount work-well-under-pressure
# 得到结果之后将其整理成为一个字典, 扫描该字典即可得到结果
4. 利用Bitmap对大文件进行排序
这一小节的应用就比较功利了, 因为对磁盘大文件进行排序, 并且限制了内存使用不能超过50M的情况下, 在日常开发中出现的频次还是极低的。
问题描述: 一个最多包含1000万个正整数的文件, 每个数的大小都小于10000000, 且数据没有重复。 如何在内存使用小于50M的情况下, 对该文件进行排序。
由于内存以及效率的限制(使用归并排序会造成多次磁盘读取), 这个问题最佳的解决方案就是使用Bitmap。 在内存中建立一个包含有1000万个bit的数组, 依次写入文件中的数字, 而后再顺序输出即可。 伪代码如下:
# 初始化bit数组
for i in range(0, n):
bit[i] = 0
# 数据逐行写入bit数组
with open("file.txt", r) as f:
while True:
data = f.readline()
if not data:
break
bit[data.strip()] = 1
# 数据逐个输出
for i in data:
if i == 1:
write i on output file
5. 小结
我记得Bitmap这个数据结构在Java中有内置的实现, 并且Guava包也对Bitmap进行了实现和优化, 至于Python, 似乎只有第三方包实现了该结构。 总的来说我们不用从零开始去编写, Redis也为我们提供了丰富的API。
Bitmap最常用的场景依然是海量数据的去重以及判断某一个数是否在海量数据当中, 除此之外就是日常的小功能实现, 例如标签统计, 网站访客信息记录等等。