Resource Group (下面简称 RG) 是 Greenplum 中用于管理内存和 CPU 资源的一个资源管理器。和 Resource Queue 相比,Resource Group 除了能够限制查询语句所使用的内存资源和并发数量以外,还通过使用 Linux Control Group 限制了 CPU 资源的使用。
1. Greenplum 6 内存控制概览
对于内存资源的管理,RG 在内部使用了 3 个作用域范围不一样的账本,包括本地 slot,当前 group 以及全局内存账本。当我们使用 palloc() 申请内存时,首先向本地 slot 账本记账,若本地 slot 账本没有足够内存则向当前 group 所在账本记账,如果当前 group 账本也没有足够的内存的话,则向全局账本进行记账。当然,如果全局账本剩余内存也不够此次申请的内存时,则 palloc() 失败。
记账的核心代码位于 groupDecMemUsage() 函数中:
static int32
groupDecMemUsage(ResGroupData *group, ResGroupSlotData *slot, int32 chunks)
{
int32 value;
int32 slotMemUsage;
int32 sharedMemUsage;
/* Sub chunks from memUsage in group */
value = pg_atomic_sub_fetch_u32((pg_atomic_uint32 *) &group->memUsage,
chunks);
Assert(value >= 0);
/* Sub chunks from memUsage in slot */
slotMemUsage = pg_atomic_fetch_sub_u32((pg_atomic_uint32 *) &slot->memUsage,
chunks);
/* Check whether shared memory should be subed */
sharedMemUsage = slotMemUsage - slot->memQuota;
if (sharedMemUsage > 0)
{
/* Decide how many chunks should be counted as shared memory */
int32 deltaSharedMemUsage = Min(sharedMemUsage, chunks);
/* Sub chunks from memSharedUsage in group */
int32 oldSharedUsage = pg_atomic_fetch_sub_u32((pg_atomic_uint32 *) &group->memSharedUsage,
deltaSharedMemUsage);
/* record the total global share usage of current group */
int32 grpTotalGlobalUsage = Max(0, oldSharedUsage - group->memSharedGranted);
/* calculate the global share usage of current release */
int32 deltaGlobalSharedMemUsage = Min(grpTotalGlobalUsage, deltaSharedMemUsage);
/* add chunks to global shared memory */
pg_atomic_add_fetch_u32(&pResGroupControl->freeChunks,
deltaGlobalSharedMemUsage);
return deltaGlobalSharedMemUsage;
}
return 0;
}
如果你对上述代码有一些疑问的话,可以通过下面的图例来尝试理解 RG 在每次申请内存时的行为。
在下面的图例中,我们假设当前 slot 所能分配的最大内存为 100 chunk (RG 使用 chunk 作为内存分配的最小单位,以减少不必要的函数调用,默认为 1MB),并且当前 slot 已经使用了 80 个 chunk,此次申请 30 个 chunk。
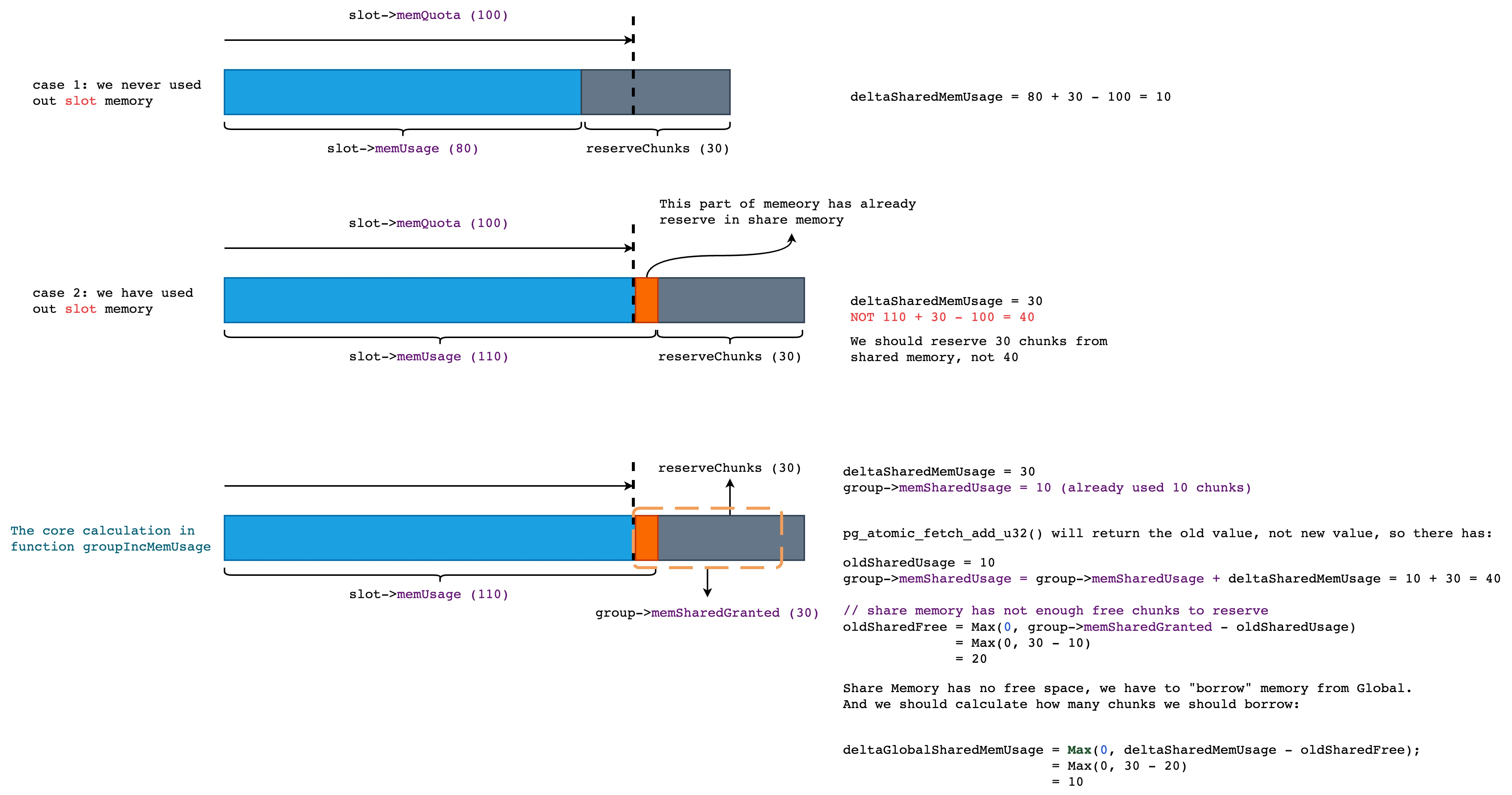
很明显,80 (used) + 30 (current need) 大于 100,因此我们需要从当前 group 的共享内存(PS:这里的共享内存并不是 Linux Shared Memory)中继续申请当前 slot 不足以分配的内存。那么这部分的内存是多少呢? 答案就是上图中的 deltaSharedMemUsage,结果为 10。也就是说我们需要从当前 group 的共享内存中再取 10 个 chunk,但是这部分的共享内存也用完了,那么我们就只能从全局的共享内存中获取,最终,我们需要从全局中再取出 10 个 chunk 才能满足此次内存分配的需求。
2. Greenplum 7 资源控制
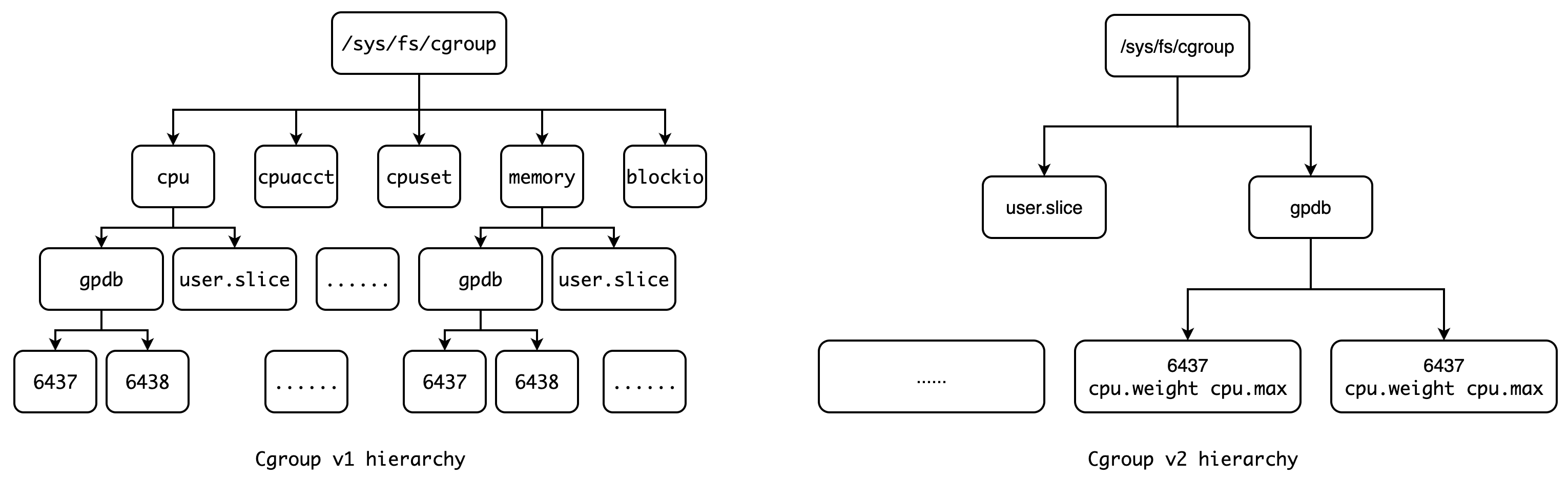
2.1 支持 Linux Cgroup v2
目前,Linux Cgroup v2 已经较为稳定,并且相比于 v1,v2 在接口层面有着相当大的改进,使用 cgroup.subtree_control 来控制孩子节点所能控制的资源,将 CPU,I/O,Memory 以及 CPUSET 等资源全部拉平到同一个目录中,不再额外划分 cpu, cpuacct 以及 cpuset 等子目录。同时,v2 禁止在非叶子节点添加进程,这一改进进一步提高了 Cgroup 的可用性,使我们不必再纠结父、子之间的资源使用比例:
更多关于 Linux Cgroup v2 的内容可参考官方文档: Control Group v2。
由于 Cgroup v1 和 Cgroup v2 的虚拟文件结构并不一样,因此在具体的实现中必须支持两种不同的文件路径和不同的虚拟文件名称。例如在 v1 中控制 cpu 上限的虚拟文件为 cpu.cfs_period_us 和 cpu.cfs_quota_us,而在 v2 中合并成了一个文件,名为 cpu.max。所以,我们必须对现有的 RG 代码进行抽象,使得上层代码不依赖具体的 Cgroup 实现,只依赖其抽象,其实就是依赖反转原则。
这部分的工作已由 refactor the original cgroup code and abstract the corresponding interface 完成。
2.2 新的 CPU 资源管理方式
在目前的 CPU 资源管理实现中,Greenplum 使用 gp_resource_group_cpu_ceiling_enforcement 这个 GUC 来决定我们如何使用底层的 Linux Cgroup,这个 GUC 的含义是是否使用绝对比例来限制 CPU 资源。
当这个 GUC 被设置为 true 时,则会修改 /sys/fs/cgroup/gpdb 的 cpu.cfs_period_us 为具体值,也就是以绝对比例限制 CPU 的使用。当这个 GUC 被设置为 false 时,则表示以相对比例来限制 CPU 资源,此时便修改 /sys/fs/cgroup/gpdb 的 cpu.shares 以相对权重的方式来限制各个子 group 所能使用的 CPU 资源。
由于这个 GUC 是全局的,因此我们无法对某个单独的 group 进行特殊的限制。所以,我们将对外暴露 Cgroup 的全部功能,不再使用该 GUC 进行全局控制。
postgres=# select * from gp_toolkit.gp_resgroup_config ;
groupid | groupname | concurrency | cpu_hard_quota_limit | cpu_soft_priority | cpuset
---------+---------------+-------------+----------------------+-------------------+--------
6437 | default_group | 20 | 20 | 100 | -1
6438 | admin_group | 10 | 10 | 100 | -1
6441 | system_group | 0 | 10 | 100 | -1
(3 rows)
上述结果为重构后的 gp_toolkit.gp_resgroup_config 视图返回,目前 memory model 的重构还在进行之中,因此并未添加至其中。
配置 cpu_hard_quota_limit 对应修改 cpu.cfs_period_us,配置 cpu_soft_priority 对应修改 cpu.shares,配置 cpuset 则对应修改 cpuset.cpus。
关于 cpu.cfs_period_us 和 cpu.shares 的具体含义可以参考文章 关于 Linux Cgroup 的一些个人理解,此处不再赘述。
那么对于一个 group 来说,我们到底该如何去配置上述参数呢?
concurrency 非常好理解,限制一个 group 所能并发执行的事务数量,按需配置即可。
cpu_hard_quota_limit 表示当前 group 中所有事务所能使用的 CPU 资源上限,cpu_hard_quota_limit=20 表示当前 group 能够使用的 CPU 资源上限为当前机器所有 CPU 资源的 20%。 通俗来讲,如果 Host 有 10 个 CPU,那么该配置就代表当前 group 最多能使用 2 个 CPU。如果我们需要严格限制某一个组别的 CPU 资源使用,可以将其设置为低于 100 的某个数值。否则,将其设置为 100 或者 -1 即可,允许该组别在其他 group 空闲的情况下使用当前 Host 的所有 CPU 资源,以达到充分利用 CPU 资源的目的。
cpu_soft_priority 表示当前 group 使用 CPU 的优先级,这个值只有在当前 Host 达到满负载运行时才有意义,也就是我们得到了如下 htop 输出:

假设有如下两组 group,其配置为:
groupid | groupname | concurrency | cpu_hard_quota_limit | cpu_soft_priority | cpuset
---------+-----------+-------------+----------------------+-------------------+--------
16384 | a | 10 | -1 | 100 | -1
16385 | b | 10 | -1 | 200 | -1
(2 rows)
它们的 cpu_hard_quota_limit 值均为 -1,即表示不对其设置 CPU 使用上限,如果它们都有能力使用完当前 Host 的所有 CPU 资源的话,那么当 a 空闲或者 b 空闲时,另一个 group 将会使用 Host 所有的 CPU 资源。但是当 a,b 都不空闲,并且火力全开的运行时,CPU 资源又该如何分配?此时就要靠 cpu_soft_priority 的值来按比例进行分配。
可以看到 a, b 两组的 cpu_soft_priority 比例为 100:200,即 1:2。因此,group a 能够获得全部 CPU 资源的 1/3,group b 能获得全部 CPU 资源的 2/3。这就是 cpu_soft_priority 含义。当然,不管分配比例如何,都不能超出 cpu_hard_quota_limit 所设定的上限。
2.3 对只查询 catalog 的单条 SQL 语句直接放行
RG 除了能够限制计算资源以外,同时还使用 slot 的方式限制并发执行的事务 数量。实现方式类似于计数器,当我们指定了一个 group 的并发数时,每当开启一个新的事务就拿走一个 slot,当拿完全部的 slot 时下一个事务将阻塞,直到前面事务结束并归还 slot,本质上就是令牌桶。
令牌桶的实现方式会带来一个问题,就是只查询 catalog 的单条 SQL 语句也会被阻塞,这就会导致一些图形 SQL 界面卡住无法响应,因为当我们打开一个图形管理界面时,它首先就会查询 catalog 来获取当前数据库实例存在哪些数据库,数据库中有哪些表。以 DBeaver 为例,当我们点击一个数据库时,它将向 Server 发送如下查询:
SELECT t.oid,t.*,c.relkind,format_type(nullif(t.typbasetype, 0), t.typtypmod) as base_type_name, d.description
FROM pg_catalog.pg_type t
LEFT OUTER JOIN pg_catalog.pg_type et ON et.oid=t.typelem
LEFT OUTER JOIN pg_catalog.pg_class c ON c.oid=t.typrelid
LEFT OUTER JOIN pg_catalog.pg_description d ON t.oid=d.objoid
WHERE t.typname IS NOT NULL
AND (c.relkind IS NULL OR c.relkind = 'c') AND (et.typcategory IS NULL OR et.typcategory <> 'C');
可以看到全部是针对 catalog 的查询。因此,对于只查询 catalog 的单条 SQL 语句将会采用 Bypass 模式,不再对其进行阻塞,即使当前 group 已经没有足够的 slot 可用。
这部分工作将由 Try to bypass query with only catalog tables 完成。
2.4 将 Postmaster、WAL Writer、Checkpointer 等进程统一归入至 system_group
在 Cgroup v1 中,允许用户在 Cgroup 的叶子结点和非叶子节点添加进程,这样一来我们很难控制父 group 和子 group 之间的资源分配,同时我们也无法知道他们之间的分配比例是多少。以下图为例:
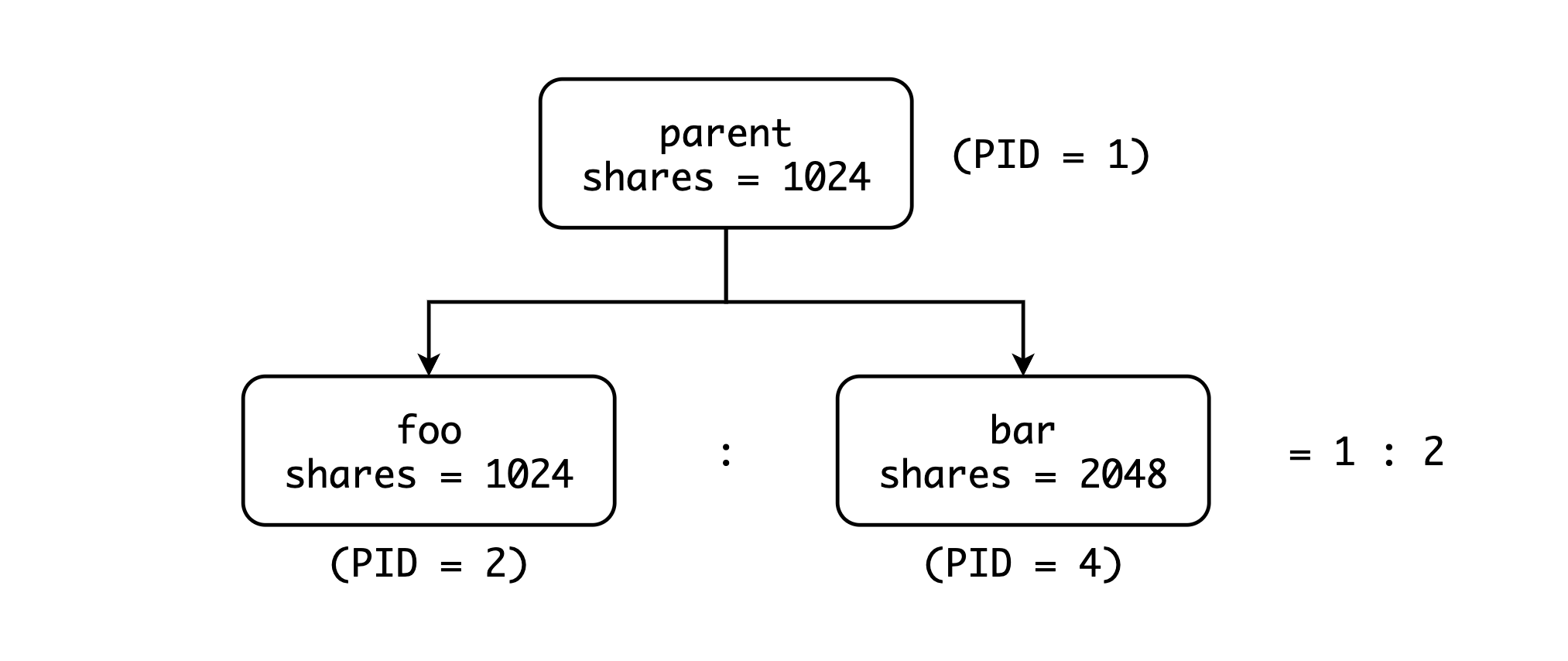
我们可以很清楚的知道 foo 和 bar 之间的 CPU 分配比例为 1024:2048,也就是 1:2。但是 parent 和 foo 之间呢? parent 和 bar 之间呢? Cgroup 的资源分配是首先将资源分配给 parent,然后 parent 将这部分资源再分配给 child。那么问题来了,parent 会使用多少资源?这个问题官方文档也并未提及,所以在后续的 Cgroup v2 中只允许在叶子结点中添加进程。
在 Greenplum 7 中,我们将所有的 Postmaster 进程和辅助进程(WAL Writer, Checkpointer 等)全部添加至了 system_group 中,不再添加至 gpdb 父组中,使得终端用户可以自行控制 Postmaster 等辅助进程的资源使用比例。
这部分的内容已由 add postmaster and all auxiliary processes to a same cgroup 完成。