第一次用“庖丁解牛”作为标题,多少还是有些不自量力的,尽管我对 PostgreSQL 的理解仍然只是停留在一个非常浅显的阶段,但是我想尽我所能的把一件事情讲清楚,并且完成从“明白”到“理解”的进步。BRIN Index 是 PostgreSQL 中非常年轻的索引,索引原理和具体实现都不复杂,是着手 PostgreSQL AM 一个非常好的切入点。
1. BRIN Index 的基本使用
这部分的内容比较简单,同时也有许多优秀的博客和文章告诉我们 BRIN Index 是什么和如何使用,所以直接“拿来”:
- Postgres Indexing: When Does BRIN Win?
- brin-intro
- When to use BRIN indexes in Postgres, tuning pages_per_range and determining correlation with pg_stats
2. BRIN Index 物理存储结构
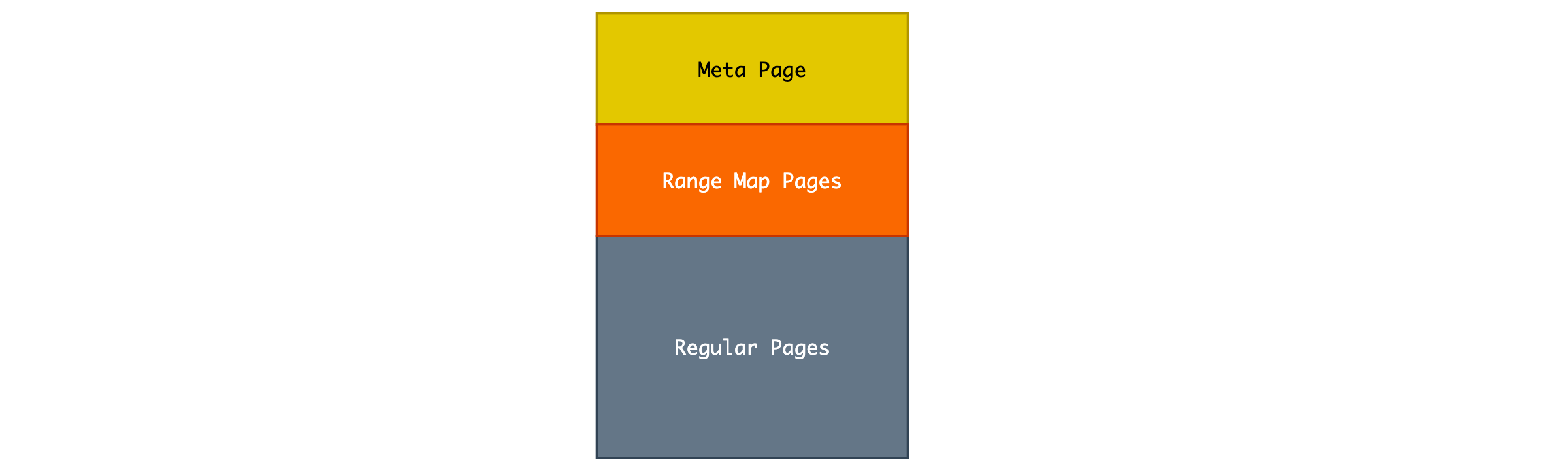
BRIN Index 文件同样由一页一页的 Page 所组成,这是 PostgreSQL 磁盘内容管理的基本,一共有 3 种类型的 Page,其组织方式如下:
2.1 Meta Page
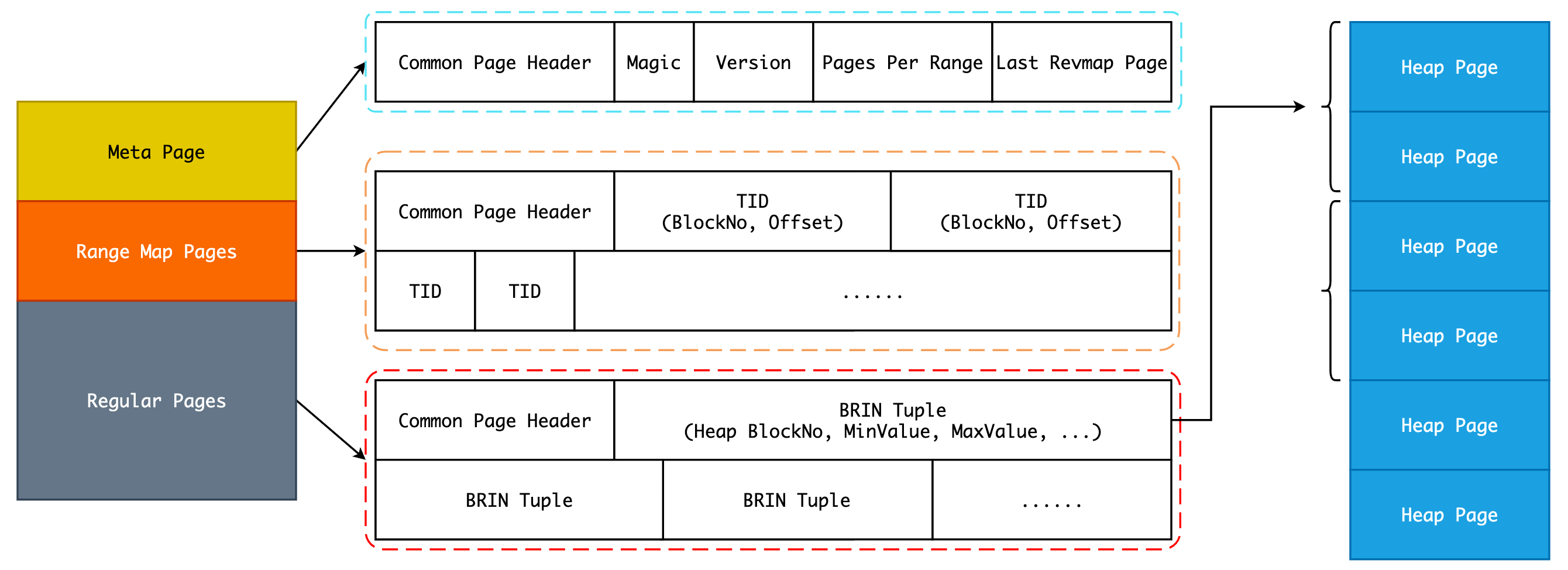
Meta Page 正如其名称所示,用于存储 BRIN Index 的元信息,有且只有一页,在内存中使用 BrinMetaPageData 表示:
typedef struct BrinMetaPageData
{
uint32 brinMagic; /* Magic Number */
uint32 brinVersion; /* 版本号 */
BlockNumber pagesPerRange; /* 建表时指定的 pages per range */
BlockNumber lastRevmapPage; /* 最后一页 Range Map */
} BrinMetaPageData;
我们可以通过 pageinspect 工具来具体的查看某一个 BRIN Index 的元信息,此时我们需要使用到函数 brin_metapage_info():
create table logs (created_at timestamp, sale int);
create index brin_idx_created_at on logs using brin(created_at) with (pages_per_range=1);
create extension pageinspect;
select * from brin_metapage_info(get_raw_page('brin_idx_created_at', 0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 1 | 1
(1 row)
2.2 Range Map Pages
紧接着 Meta Page 的是一页或多页的 Range Map Pages,本质上是一个 Item Pointer 数组,存储着索引数据的 TID。之前我们已经明白了 BRIN Index 其实就是汇总指定数量个(pages_per_range) Heap Blocks 的最大/最小值,这个最大/最小值将会被存储在一个 BRIN Tuple 中,为了快速在索引文件中找到这个 BRIN Tuple,PostgreSQL 额外引入了一个连续的 TID 数组,也就是 Range Map Pages。
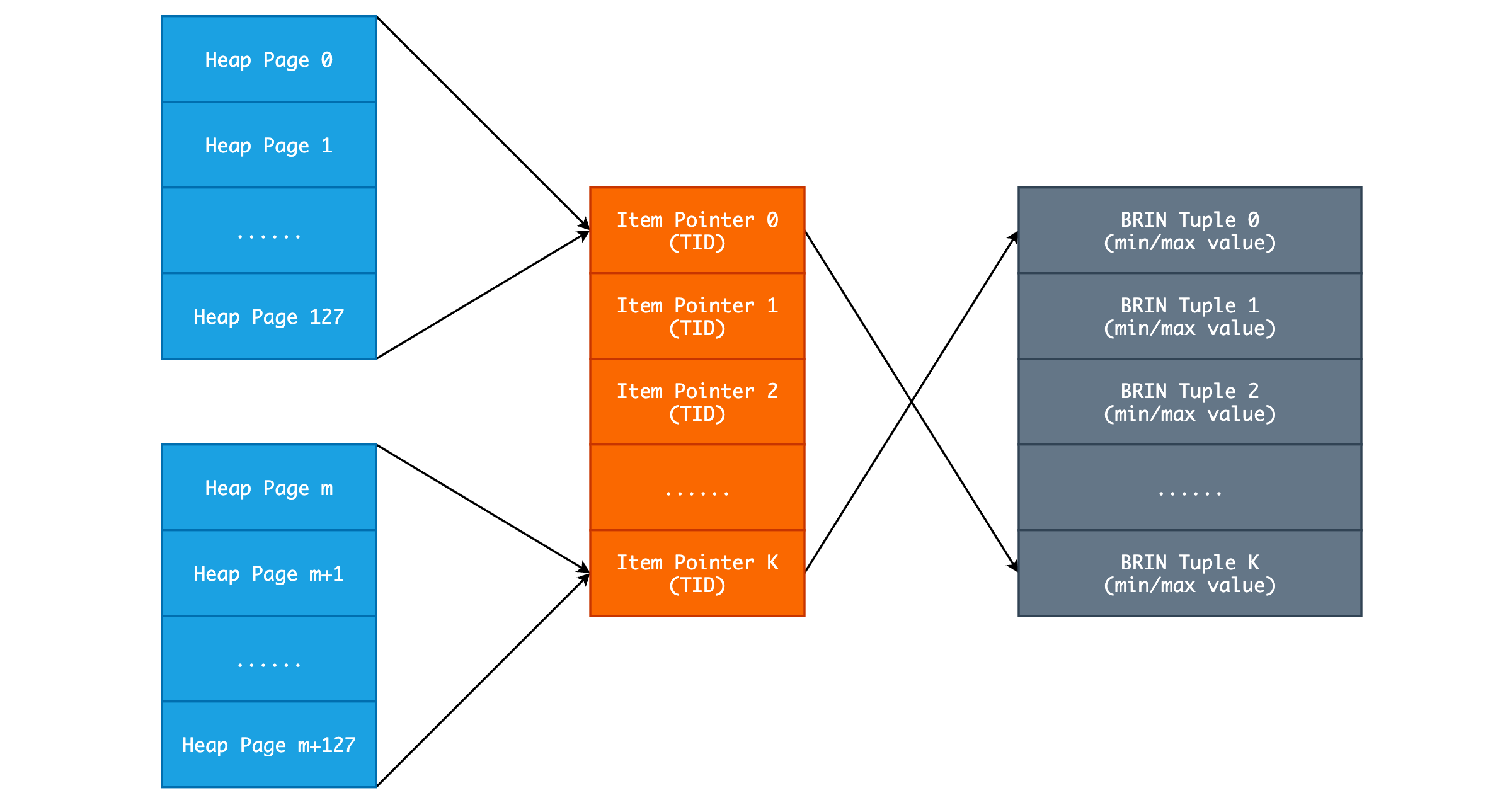
如上图所示,在默认情况下,每 128 个 Heap Pages 将会计算一次汇总数据并保存在 BRIN Tuple 中。而对于 Range Map Page 来说,其内容大小是固定的,除去常规 Page Header 以外,其余全部空间都用来保存 6 字节大小的 Item Pointer。
如此一来,我们就可以通过简单的计算来迅速定位某一个 Heap Page 的总结信息在哪一个 Range Map Page 的具体哪个位置。比如说我们想找 Heap Page 327 的总结数据,那么首先计算它在第几组: 327 / 128 = 2。然后我们记每个 Range Map Page 能存储 REVMAP_PAGE_MAXITEMS 个 TID,则可计算它在 2 / REVMAP_PAGE_MAXITEMS = 0 号 Page,偏移量为 2 % REVMAP_PAGE_MAXITEMS = 2。
同样的,我们可以通过函数 brin_revmap_data 来获取 Range Map Pages 的具体内容:
insert into logs select '2023-02-01 0:00'::timestamptz + id * interval '2 sec', id from generate_series(1,10000000) id;
vacuum logs;
select * from brin_revmap_data(get_raw_page('brin_idx_created_at',1)) limit 5;
pages
-----------
(165,168)
(165,169)
(165,170)
(165,171)
(165,172)
(5 rows)
2.3 Regular Pages
在 Regular Pages 保存的就是汇总数据,即 BRIN Tuple,具体可参考上图。有一点需要值得注意的是,BRIN Tuple 并不是顺序存放的,原因我们稍后再来讨论。
通过函数 brin_page_items() 可查看 Regular Pages 的具体内容:
select * from brin_page_items(get_raw_page('brin_idx_created_at',47),'brin_idx_created_at') limit 5;
itemoffset | blknum | attnum | allnulls | hasnulls | placeholder | value
------------+--------+--------+----------+----------+-------------+----------------------------------------------
1 | 1924 | 1 | f | f | f | {2023-02-09 05:44:42 .. 2023-02-09 05:50:50}
2 | 1925 | 1 | f | f | f | {2023-02-09 05:50:52 .. 2023-02-09 05:57:00}
3 | 1926 | 1 | f | f | f | {2023-02-09 05:57:02 .. 2023-02-09 06:03:10}
4 | 1927 | 1 | f | f | f | {2023-02-09 06:03:12 .. 2023-02-09 06:09:20}
5 | 1928 | 1 | f | f | f | {2023-02-09 06:09:22 .. 2023-02-09 06:15:30}
(5 rows)
2.4 小结
最后,我们可以通过下图来对 BRIN Index File Pages 有一个更清晰的认知:
3. BRIN Index Access Method
接下来,我们就需要进入到 BRIN Index 的一系列访问方法,从而明白当我们在插入、更新、删除以及查询时 BRIN Index 是如何工作的,同时这些操作也正是组成一个索引的核心内容。触类旁通,我们也可以用同样的方式去分析其它索引的运作方式。
PG Catalog 中有一张表就叫做 pg_am,通过查询该表我们可以获得所有 AM 的处理 Handler:
postgres=# select * from pg_am;
oid | amname | amhandler | amtype
------+--------+----------------------+--------
2 | heap | heap_tableam_handler | t
403 | btree | bthandler | i
405 | hash | hashhandler | i
783 | gist | gisthandler | i
2742 | gin | ginhandler | i
4000 | spgist | spghandler | i
3580 | brin | brinhandler | i
(7 rows)
可以看到,对于 BRIN Index 来说,其 AM Handler 为 brinhandler,而这个 Handler 一定在源码中存在,我们直接翻看即可:
Datum
brinhandler(PG_FUNCTION_ARGS)
{
IndexAmRoutine *amroutine = makeNode(IndexAmRoutine);
/*......*/
amroutine->ambuild = brinbuild; /* 创建索引时该怎么做 */
amroutine->ambuildempty = brinbuildempty; /* 创建空索引时该怎么做 */
amroutine->aminsert = brininsert; /* 当heap有tuple插入时该怎么做 */
amroutine->ambulkdelete = brinbulkdelete; /* 批量删除tuple时该怎么做 */
amroutine->amvacuumcleanup = brinvacuumcleanup; /* vacuum的时候该怎么做 */
amroutine->amcostestimate = brincostestimate; /* 成本估计 */
amroutine->amoptions = brinoptions; /* 解析pages_per_range和autosummarize参数 */
amroutine->amvalidate = brinvalidate; /* 校验函数 */
amroutine->ambeginscan = brinbeginscan; /* begin scan */
amroutine->amrescan = brinrescan; /* re scan */
amroutine->amgettuple = NULL; /* BRIN是对Page的总结,所以没有点查 */
amroutine->amgetbitmap = bringetbitmap; /* bitmap index scan */
amroutine->amendscan = brinendscan; /* end scan */
PG_RETURN_POINTER(amroutine);
}
如上所示,当我们需要创建一个属于我们自己的索引时,这些函数就是必须要实现的函数。
3.1 数据查询
BRIN Index 在每一次扫描时都会扫描整个索引文件,并不像 B-Tree 那样只对搜索路径上的页面进行扫描,这是因为 BRIN Index 是一种高度概括信息,并且是由用户来保证数据之间关联性。
int64 bringetbitmap(IndexScanDesc scan, Node **bmNodeP) {
/* 打开 heap table */
heapOid = IndexGetRelation(RelationGetRelid(idxRel), false);
heapRel = table_open(heapOid, AccessShareLock);
/* 获取 heap file 有多少个 page */
nblocks = RelationGetNumberOfBlocks(heapRel);
/* 从第 0 个 page 开始读取,每隔 pages per range 读取一个 page
* 这里不从 rang map 读取的原因就在于 range map 可能会发生并发更新,从而导致读取出来的数据不对 */
for (heapBlk = 0; heapBlk < nblocks; heapBlk += opaque->bo_pagesPerRange) {
bool addrange;
bool gottuple = false;
BrinTuple *tup;
OffsetNumber off;
Size size;
/* 获取 Brin Tuple,也就是从 Revmap 中读取到 Brin Tuple 的位置,然后再把 Brin Tuple 读出来 */
tup = brinGetTupleForHeapBlock(opaque->bo_rmAccess, heapBlk, &buf,
&off, &size, BUFFER_LOCK_SHARE, scan->xs_snapshot);
if (tup) {
gottuple = true;
btup = brin_copy_tuple(tup, size, btup, &btupsz);
LockBuffer(buf, BUFFER_LOCK_UNLOCK);
}
if (!gottuple)
addrange = true;
else {
/* 获取 BRIN Tuple,将其转换成 BrinMemTuple */
dtup = brin_deform_tuple(bdesc, btup, dtup);
if (dtup->bt_placeholder)
addrange = true;
else {
int keyno;
/* 根据扫描 key 进行对比 */
addrange = true;
for (keyno = 0; keyno < scan->numberOfKeys; keyno++) {
/* ...... */
}
}
}
/* 如果当前 BRIN Tuple 符合筛选条件的话,那么就需要将其所对应的
* pages 添加至结果中,也就是 bmNodeP 中 */
if (addrange) {
BlockNumber pageno;
/* 遍历所有的 pages */
for (pageno = heapBlk; pageno <= heapBlk + opaque->bo_pagesPerRange - 1; pageno++) {
MemoryContextSwitchTo(oldcxt);
tbm_add_page(tbm, pageno);
totalpages++;
MemoryContextSwitchTo(perRangeCxt);
}
}
}
}
3.2 数据插入
当插入数据时并不一定会导致索引块的更新。
如果插入 Tuple 所在 Heap Page 在现有的 Range Map 范围内,则会选择性的更新 summarize value,即这一范围内的最大/最小值。
如果插入 Tuple 所在 Heap Page 不在现有的 Range Map 范围内,但是指定了 autosummarize 参数,则会向 vacuum 队列发送一个 Auto Summarize 请求,对新的 Heap Pages 进行 Summarize,从而生成新的 Brin Tuple。
bool
brininsert(Relation idxRel, Datum *values, bool *nulls,
ItemPointer heaptid, Relation heapRel,
IndexUniqueCheck checkUnique,
IndexInfo *indexInfo)
{
revmap = brinRevmapInitialize(idxRel, &pagesPerRange, NULL);
/* origHeapBlk 表示发生 tuple 插入的 heap page. heapBlk
* heapBlk 则表示该 heap page 所在组的第一个 heap page */
origHeapBlk = ItemPointerGetBlockNumber(heaptid);
heapBlk = (origHeapBlk / pagesPerRange) * pagesPerRange;
for (;;) {
/* 在建立索引时指定了 autosummarize 为 true,同时插入的 tuple page 是
* summarize 的第一个 page */
if (autosummarize && heapBlk > 0 && heapBlk == origHeapBlk &&
ItemPointerGetOffsetNumber(heaptid) == FirstOffsetNumber) {
BlockNumber lastPageRange = heapBlk - 1;
BrinTuple *lastPageTuple;
/* 获取上一页的 Brin Tuple */
lastPageTuple = brinGetTupleForHeapBlock(revmap, lastPageRange, &buf, &off,
NULL, BUFFER_LOCK_SHARE, NULL);
if (!lastPageTuple) {
/* 发送 vacuum 请,类型为 AVW_BRINSummarizeRange */
recorded = AutoVacuumRequestWork(AVW_BRINSummarizeRange,
RelationGetRelid(idxRel), lastPageRange);
}
else
LockBuffer(buf, BUFFER_LOCK_UNLOCK);
}
/* 获取 BRIN Tuple */
brtup = brinGetTupleForHeapBlock(revmap, heapBlk, &buf, &off, NULL, BUFFER_LOCK_SHARE, NULL);
/* if range is unsummarized, there's nothing to do */
/*
* 注意这个地方,如果当前 range 没有进行 summarize 的话,将会直接跳过。
* 那么为什么不在这里进行 summarize 呢? 原因在于 summarize 是一个很耗时的过程,需要扫描 pages per range 个
* page 从而找到 max/min value,这里 PG 将其设计成异步更新,即 summarize 的过程只由 vacuum 进程来做。
* 这样一来索引数据的插入不会影响 heap data 的插入效率 */
if (!brtup)
break;
dtup = brin_deform_tuple(bdesc, brtup, NULL);
/* 逐一对 Index Key 进行比较,如果该值大于最大值或者是小于最小值的话,需要更新 BRIN Tuple values */
for (keyno = 0; keyno < bdesc->bd_tupdesc->natts; keyno++)
{
/* ...... */
/* if that returned true, we need to insert the updated tuple */
need_insert |= DatumGetBool(result);
}
if (!need_insert)
LockBuffer(buf, BUFFER_LOCK_UNLOCK);
else {
/* 更新 BRIN Tuple */
if (!brin_doupdate(idxRel, pagesPerRange, revmap, heapBlk,
buf, off, origtup, origsz, newtup, newsz,
samepage, false)) {
/* no luck; start over */
MemoryContextResetAndDeleteChildren(tupcxt);
continue;
}
}
/* success! */
break;
}
return false;
}
3.3 数据删除与更新
和其他索引一样,当我们删除数据时,并不会去更新 BRIN Index,而是由 vacuum 进程进行批量删除。而对于更新来说,本质上是插入+删除数据,因此对索引的影响如上所述。
3.4 数据的 summarize
数据的 summarize 是 BRIN Index 中非常重要的操作,这直接关系着索引的高效性。一方面频繁的 summarize 使得索引数据更加准确,执行过程将会更高效。另一方面这也会引入额外的 CPU 和 I/O 开销,因此 PostgreSQL 引入了 autosummarize 这个参数来让用户决定是否自动的进行 summarize。
首先,我们需要知道 AVW_BRINSummarizeRange 类型的 vacuum type 对应着哪个处理函数,通过源码可知会调用 brin_summarize_range_internal() 函数,而这个函数的本质就是调用 brinsummarize() 对某一个 Heap Page 进行 summarize。
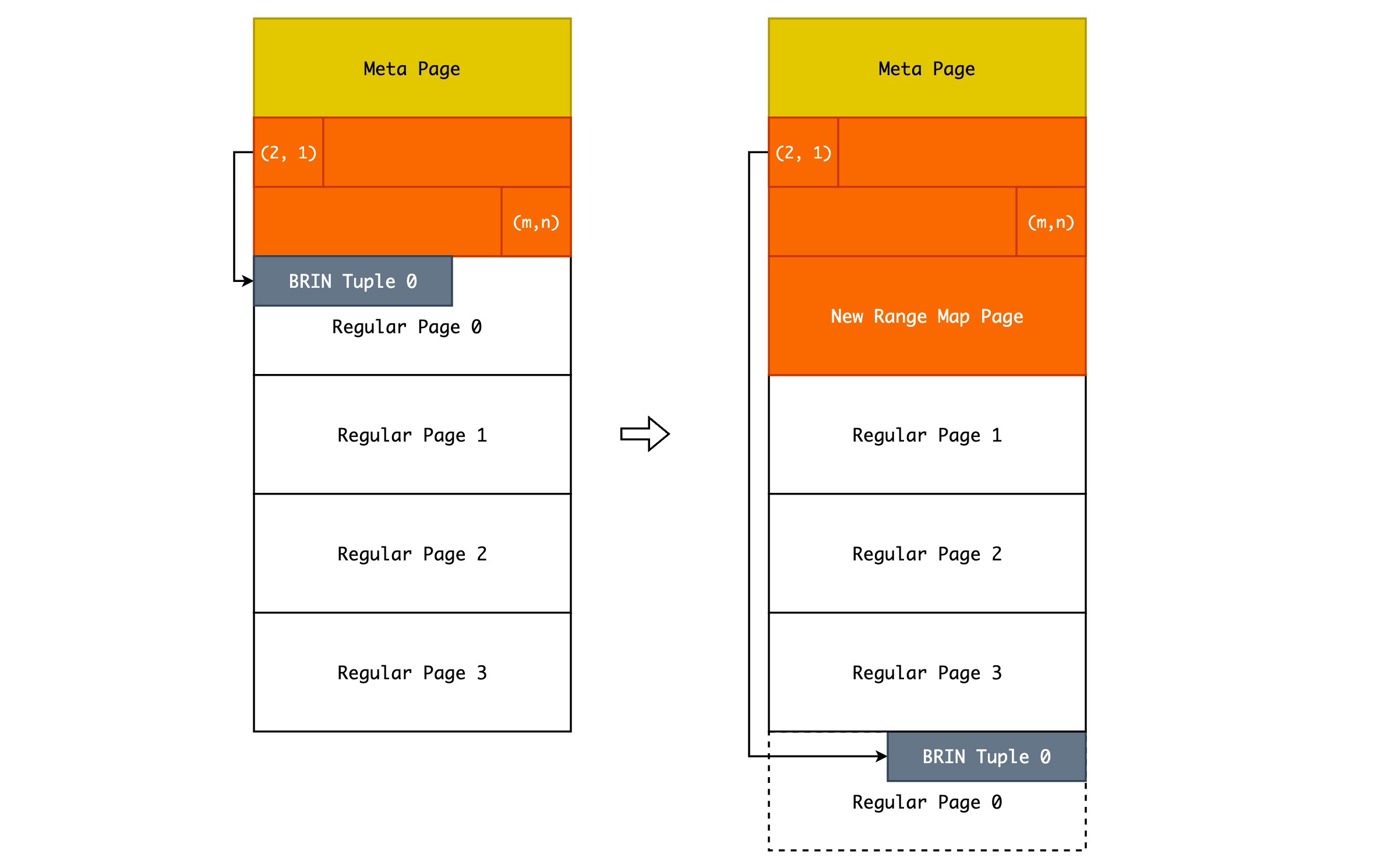
在一般情况下,我们只需要扫描新增的 Heap Pages,得到该范围内的最大/最小值,然后在 Range Map 和 Regular Page 中新增一项数据即可。但是如果说现在的 Range Map 已经满了,无法插入一个新的 ItemPointer,该如何处理呢?
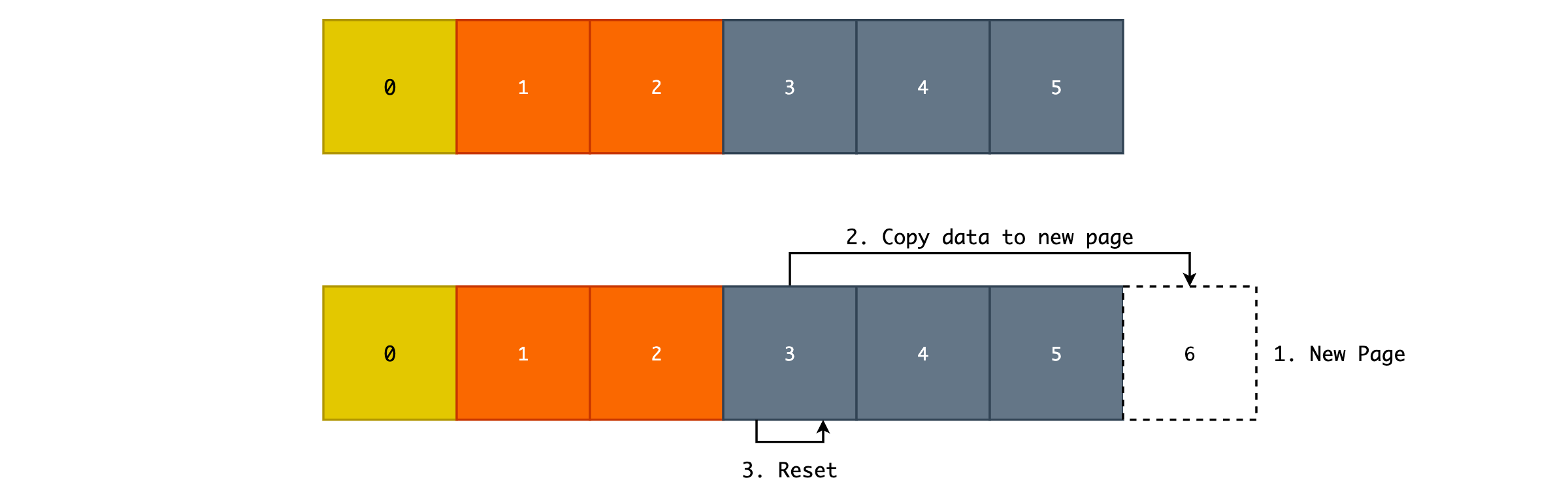
如上图所示,2 号是最后一个已满的 Range Map Page,3 号是第一个 Regular Page。当 2 号已满时,我们会在文件尾部再生成一个 Page,并将 3 号页面的所有数据拷贝过去,再将 3 号 Page 的内容清空,作为新的 Range Map Page。这就是为什么在 Regular Pages 中的数据并不是有序存储的原因,因为需要腾笼换鸟,以保证 Range Map Pages 的连续性。
3.5 从索引文件初始化到数据的插入
接下来我们就来探索一下 BRIN Index File 从初始化到有数据持续的插入过程中,Range Map Pages 和 Regular Pages 所发生的变化。
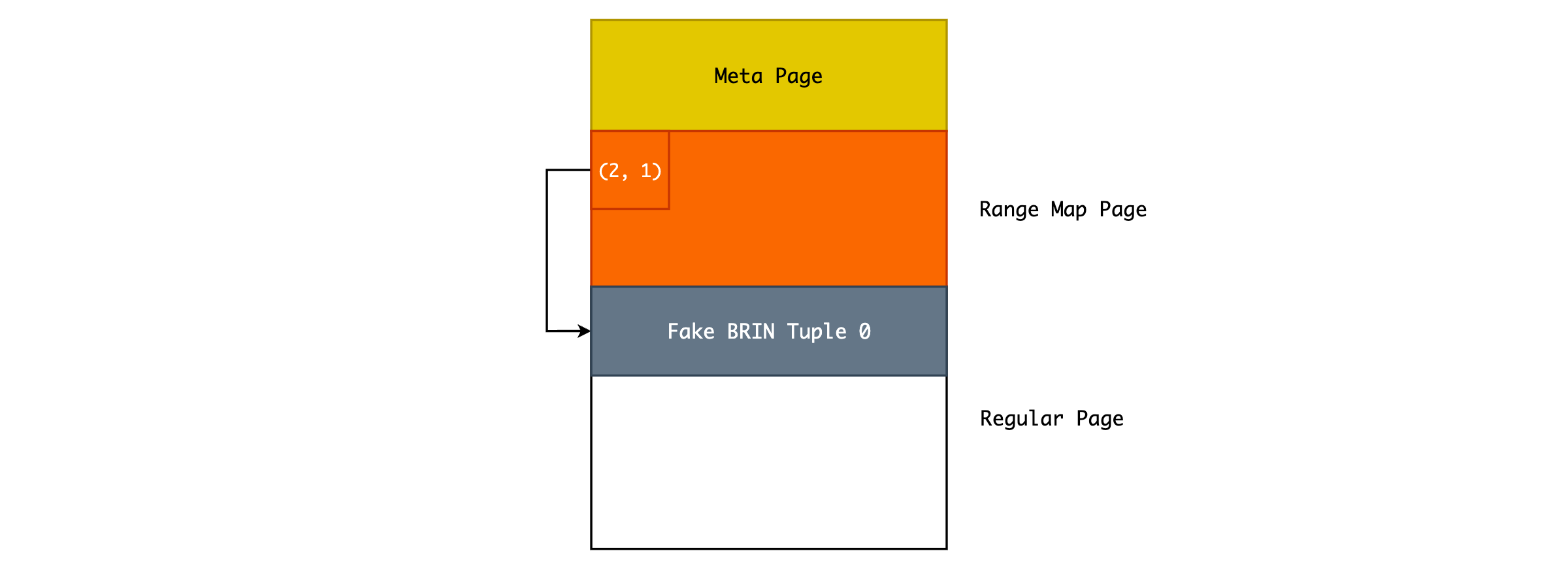
当我们为空表创建索引时,由于 Heap Table 中没有 Tuple,那么也就没有办法对某一个范围内的 Pages 创建 summarize 信息。但是,为了方便后续的数据插入,PostgreSQL 会初始化一个虚拟的 BRIN Tuple,作为一个占位符:
create table logs (created_at timestamp, sale int);
create index brin_idx_created_at on logs using brin(created_at) with (pages_per_range=1, autosummarize=true);
create extension pageinspect;
select * from brin_metapage_info(get_raw_page('brin_idx_created_at', 0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 1 | 1
(1 row)
select * from brin_revmap_data(get_raw_page('brin_idx_created_at',1)) limit 2;
pages
-------
(2,1)
(0,0)
select * from brin_page_items(get_raw_page('brin_idx_created_at',2),'brin_idx_created_at');
itemoffset | blknum | attnum | allnulls | hasnulls | placeholder | value
------------+--------+--------+----------+----------+-------------+-------
1 | 0 | 1 | t | f | f |
可以看到,初始化的 BRIN Index File 的 Range Map Page 并不是全部为空,而是给第一个 Per Pages 预先生成了一个 TID 和与之对应的 BRIN Tuple,只不过该 Tuple 的 value 值为空。
insert into logs select '2023-02-01 0:00'::timestamptz + id * interval '2 sec', id from generate_series(0,4) id;
select * from logs;
created_at | sale
---------------------+------
2023-02-01 00:00:00 | 0
2023-02-01 00:00:02 | 1
2023-02-01 00:00:04 | 2
2023-02-01 00:00:06 | 3
2023-02-01 00:00:08 | 4
select itemoffset,blknum,value from
brin_page_items(get_raw_page('brin_idx_created_at',2),'brin_idx_created_at');
itemoffset | blknum | value
------------+--------+----------------------------------------------
1 | 0 | {2023-02-01 00:00:00 .. 2023-02-01 00:00:08}
当我们插入了 5 条数据以后,按照前面 brininsert() 函数的逻辑,将会更新该 Tuple 所在 Page 的 summarize 信息,即更新最大/最小值。
当我们继续插入数据时,Range Map Page 中的空间会不断地被使用,直到没有多余的空间再存储一个 Item Pointer,此时就需要扩展 Range Map Page:
insert into logs select '2023-02-01 0:00'::timestamptz + id * interval '2 sec', id from generate_series(5,300000) id;
vacuum logs;
select * from brin_metapage_info(get_raw_page('brin_idx_created_at', 0));
magic | version | pagesperrange | lastrevmappage
------------+---------+---------------+----------------
0xA8109CFA | 1 | 1 | 2
select * from brin_revmap_data(get_raw_page('brin_idx_created_at',1)) limit 2;
pages
---------
(6,197)
(6,198)
select itemoffset,blknum,value from
brin_page_items(get_raw_page('brin_idx_created_at',6),'brin_idx_created_at') where itemoffset = 197;
itemoffset | blknum | value
------------+--------+----------------------------------------------
197 | 0 | {2023-02-01 00:00:00 .. 2023-02-01 00:06:08}
可以看到,由于扩展 Range Map Page 的原因,原来的第一页 Regular Page 被置换到了第 7 页。