Kubernetes 声明式API的核心就在于用户提交的YAML文件表示期望状态,Kubernetes 需要根据该期望状态与集群实际状态进行对比,并根据对比的结果作出相应的操作。期望状态由 APIServer 保存在 Etcd 中,Kubernetes 对资源进行调谐时,是否均需要通过 APIServer 查询 Etcd 来获取期望状态呢?
1. ListAndWatch机制
在 Kubernetes 中,集群的状态、用户提交的YAML文件均保存在Etcd数据库中,而获取这些数据的唯一方法就是通过 APIServer。APIServer 与 Etcd 通过 RPC 进行通信,对外则暴露需要鉴权的 REST API 接口,用户可通过这些API接口间接地获取集群状态。例如kubectl工具就是通过封装 APIServer 的 REST API 进行工作的。
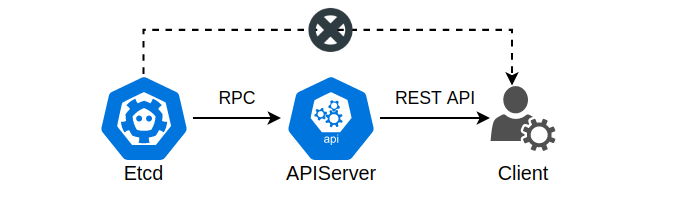
除了通用的GET、POST的API以外,APIServer 还提供了可用于持续监听的 Watch API。顾名思义,Watch API 本质上就是一种 APIServer 主动向客户端推送 Kubernetes 资源修改、创建的一种机制,默认采用 HTTP/1.1 的分块传输实现,同时也可以使用 websocket 协议进行信息接收。
以获取Pod事件为例,通过调用/api/v1/watch/namespaces/{namespace}/pods?watch=yes可使得客户端与 APIServer 建立HTTP长连接,每当集群中出现了 Pod 的相关事件(创建、更新等),APIServer 将会通过该连接将对应的事件推送至客户端。实际上,Watch API 就是一种增量更新,如同MySQL主从复制中的Binlog数据传输。
当然,在进行资源的增量更新之前,首先要获取到当前集群中资源的存量信息,可通过 List API 获得: /api/v1/namespaces/{namespace}/pods。通过 List API 获取集群当前某资源的全部信息,以及通过 Watch API 获取资源的增量信息,在 Kubernetes 中称为 ListAndWatch 机制,是 APIServer 的核心机制之一。
关于kubernetes-api的更多信息可查看官网: https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.18/#-strong-api-overview-strong-
2. Informer工作原理
既然客户端可以使用 ListAndWatch 机制来实时地同步 Kubernetes 中某类资源的状态,那么在 Kubernetes 内部,同样可以使用该机制从 APIServer 中接收资源的变化,从而建立本地缓存减轻 APIServer 与 Etcd 的负载,并且实现 Kubernetes 中的控制器模式。该内部组件称之为 Informer,中文译为通知器。
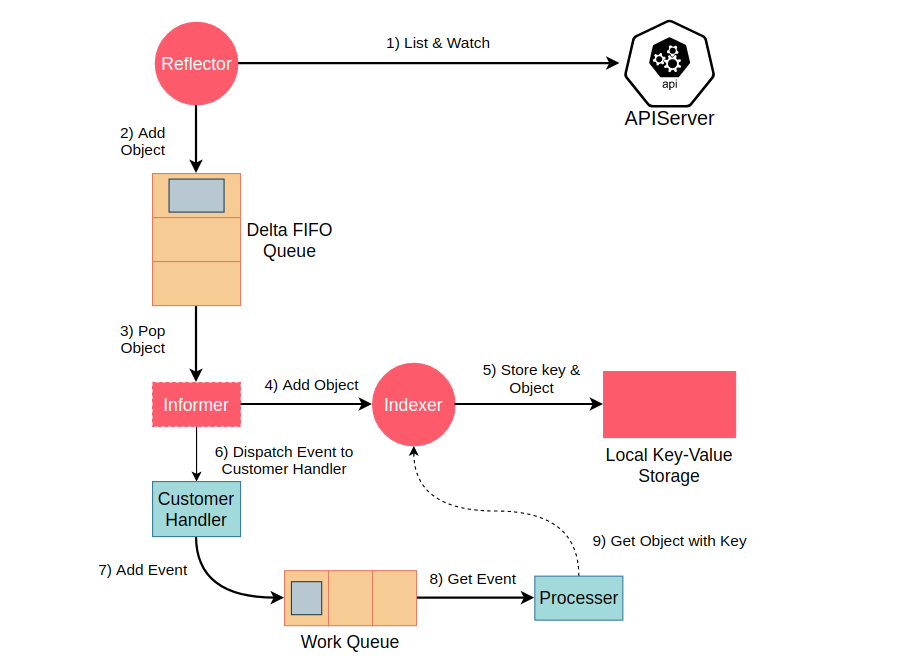
首先,Reflector 包会和 APIServer 建立长连接,并使用 ListAndWatch 方法获取并监听某一个资源的变化。List 方法将会获取某个资源的所有实例(如ReplicaSet、Deployment等),Watch 方法则监听资源对象的创建、更新以及删除事件,获取到的事件称之为一个增量(Delta),该增量会被放进一个称之为 Delta FIFO Queue,即增量先进先出队列中。
而后,Informer会不断的从 Delta FIFO Queue 中 pop 增量事件,并根据事件的类型来决定新增、更新或者是删除本地缓存,也就是 Local Key-Value Sotrage。根据集群中某资源的事件来更新本地缓存是Informer的第一个职责,同时也是最重要的职责。
Informer 的另外一个职责就是根据事件类型来触发事先注册好的 Event Handler。在回调函数中通常只会做一些简单的过滤处理,然后将该事件丢到 Work Queue 这个工作队列中。工作队列的主要作用就是平衡 Informer 和 Controller 之间的速度差,避免 Controller 处理速度过慢而影响 Informer 的工作。
接下来就是 Controller 的表演时间了,也就是上图中的 Processer。控制器从 Work Queue 中取出一个事件并根据自身的业务逻辑对其进行处理,不同的控制器会有不同的处理逻辑。如 ReplicSet 控制器在收到某一个 Pod 被删除的事件时将会重新创建一个 Pod,以保证 Pod 的数量。
3. Informer代码编写流程
package main
import (
"log"
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/labels"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
)
func main() {
// 简单起见硬编码相关配置
configPath := "/home/smartkeyerror/.kube/config"
masterURL := "https://10.39.35.19:6443"
// 初始化config
config, err := clientcmd.BuildConfigFromFlags(masterURL, configPath)
if err != nil {
panic(err)
}
// 初始化client
kubeClient, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
// 获取工厂实例, 通过这个工厂实例可获取到所有资源的 Informer
factory := informers.NewSharedInformerFactory(kubeClient, 0)
// 创建Pod Informer
podInformer := factory.Core().V1().Pods()
informer := podInformer.Informer()
stopCh := make(chan struct{})
defer close(stopCh)
go factory.Start(stopCh)
if !cache.WaitForCacheSync(stopCh, informer.HasSynced) {
log.Fatal("sync failed")
}
// 注册定义处理函数(偷懒, 不使用队列, 直接print)
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
pod := obj.(*v1.Pod)
log.Println("Get a pod:", pod.Name)
},
UpdateFunc: func(oldObj, newObj interface{}) {log.Println("update pod")},
DeleteFunc: func(interface{}) {log.Println("delete pod")},
})
// 创建Lister
podLister := podInformer.Lister()
// 获取所有标签的pod
podList, err := podLister.List(labels.Everything())
if err != nil {
log.Fatal(err)
}
log.Println(podList)
<- stopCh
}
这是一个最简单的使用 Informer 的代码示例,其作用就是通过List方法打印出当前集群中所有的 Pod,以及在创建、删除和更新 Pod 资源时打印出相关的信息。
首先我们通过集群的地址以及config认证文件生成一个基本的config对象,并且根据该对象初始化了一个kubeClient对象,然后使用kubeClient创建了一个工厂实例。这个工厂实例中包含了 Kubernetes 中所有资源的 Informer,例如 Pod,Node,Network,RBAC等等。
剩下的代码内容就是按照上述的原理图按部就班的编写和执行了。实际上,对上述代码进行稍加改造即可以得到一个自定义控制器(CRD)的简易版本。控制器模式本质上就是用户期望状态和集群实际状态之间的对比、调谐,使得集群实际状态在某个时刻之后与用户期望状态一致,保存在 Informer 本地缓存的资源状态,其实就是用户的期望状态。
4. 小结
Kubernetes 可以说是一个由事件驱动的分布式对象管理中心,而 Informer 则正是提供驱动事件的发动机。从设计模式的角度来看,Informer 本质上就是一个观察者,Controller 和本地缓存就是基于该观察者所观察的结果进行相应的处理。