我们常说 Python 一是门解释型语言,只需要敲下 python code.py 就可以运行编写的代码,而无需使用类似于 javac 或者 gcc 进行编译。那么,Python 解释器是真的一行一行读取 Python 源代码而后执行吗? 实际上,Python 在执行程序时和 Java、C# 一样,都是先将源码进行编译生成字节码,然后由虚拟机进行执行,只不过 Python 解释器把这两步合二为一了而已。
1. Python 程序执行过程
事实上,Python 程序在执行过程中同样需要编译(Compile),编译产生的结果称之为字节码,而后由 Python 虚拟机逐行地执行这些字节码。所以,Python 解释器由两部分组成: 编译器和虚拟机。
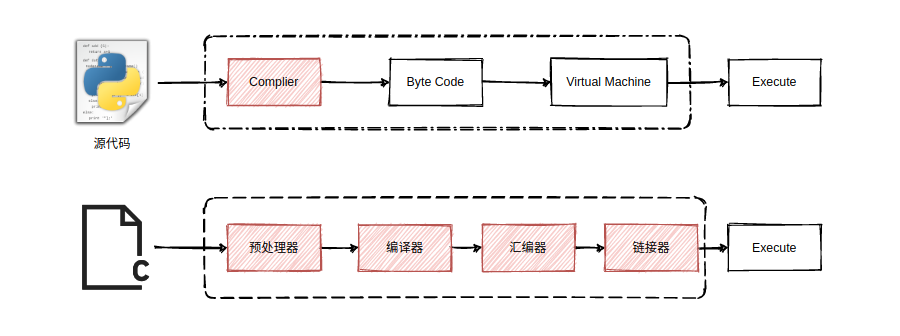
上图展示了 Python 程序的执行过程,以及C程序的编译、汇编与链接过程,从该图中可以非常明显地看出 Python 与 C 程序的执行区别。Python 如此设计的原因在于将程序的执行与底层硬件进一步地分离,无需担心程序的编译、汇编以及链接过程,使得 Python 程序相较于 C 程序而言更加易于移植。
这里再说一下 Python 和 Java 的区别。Java 在程序执行时必须使用 javac 对源代码进行编译,但是并不直接编译成机器语言,而是和 Python 一样,编译成字节码,而后由 JVM 进行执行。从这一点上来看,Python 和 Java 非常类似,只不过 Python 的编译过程由解释器完成,用户也可以手动的对 Python 源代码进行编译,生成 .pyc 文件,节省那么一丢丢的时间。
python -m compileall <dir>
通过运行上述命令可对 <dir> 目录下所有的Python文件进行编译,编译结果将会存放于该目录下的 __pycache__ 的 .pyc 文件中。
2. 编译过程与字节码
在Python的内建函数中,定义了 compile 以及 exec 两个方法,前者将源代码编译成为 Code Object 对象,Code Object 对象中即保存着源代码所对应的字节。而 exec 方法则是运行 Python 语句或者是由 compile 方法所返回的 Code Object。exec 方法可直接运行 Python 语句,其参数并一定需要是 Code Object。
>>> snippet = "for i in range(3): print(f'Output: {i}')"
>>> result = compile(snippet, "", "exec")
>>> result
<code object <module> at 0x7f8e7e6471e0, file "", line 1>
>>> exec(result)
Output: 0
Output: 1
Output: 2
在上述代码中定义了一个非常简单的 Python 代码片段,其作用就是在标准输出中打印0,1,2这三个数而已。通过 compile 方法对该片段进行编译,得到 Code Object 对象,并将该对象交由 exec 函数执行。下面来具体看下返回的 Code Object 中到底包含了什么。
在源码 cpython/Include/code.h 中定义了 PyCodeObject 结构体,即 Code Object 对象:
/* Bytecode object */
typedef struct {
PyObject_HEAD /* Python定长对象头 */
PyObject *co_code; /* 指令操作码,即字节码 */
PyObject *co_consts; /* 常量列表 */
PyObject *co_names; /* 名称列表(不一定是变量,也可能是函数名称、类名称等) */
PyObject *co_filename; /* 源码文件名称 */
... /* 省略若干字段 */
} PyCodeObject;
字段 co_code 即为 Python 编译后字节码,其它字段在此处可暂时忽略。字节码的格式为人类不可阅读格式,其形式通常是这样的:
>>> result.co_code
b'x\x1ee\x00d\x00\x83\x01D\x00]\x12Z\x01e\x02d\x01e\x01\x9b\x00\x9d\x02\x83\x01\x01\x00q\nW\x00d\x02S\x00'
这个时候我们需要一个”反汇编器”来将字节码转换成人类可阅读的格式,”反汇编器”打引号的原因是在 Python 中并不能称为真正的反汇编器。
>>> import dis
>>> dis.dis(result.co_code)
0 SETUP_LOOP 30 (to 32)
2 LOAD_NAME 0 (0)
4 LOAD_CONST 0 (0)
6 CALL_FUNCTION 1
8 GET_ITER
>> 10 FOR_ITER 18 (to 30)
12 STORE_NAME 1 (1)
14 LOAD_NAME 2 (2)
16 LOAD_CONST 1 (1)
18 LOAD_NAME 1 (1)
20 FORMAT_VALUE 0
22 BUILD_STRING 2
24 CALL_FUNCTION 1
26 POP_TOP
28 JUMP_ABSOLUTE 10
>> 30 POP_BLOCK
>> 32 LOAD_CONST 2 (2)
34 RETURN_VALUE
dis 方法将返回字节码的助记符(mnemonics),和汇编语言非常类似,从这些助记符的名称上我们就可以大概猜出解释器将要执行的动作,例如 LOAD_NAME 加载名称,LOAD_CONST 加载常量。所以,我们完全可以将这些助记符看作是汇编指令,而指令的操作数则在助记符后面描述。例如 LOAD_NAME 操作,其操作数的下标为0,而在源代码中使用过的名称保存在 co_names 字段中,所以 LOAD_NAME 0 即表示加载 result.co_names[0] :
>>> result.co_names[0]
'range'
又比如 LOAD_CONST 操作,其操作数的下标也为0,只不过这次操作数不再保存在 co_names ,而是 co_consts 中,所以 LOAD_CONST 0 则表示加载 result.co_consts[0] :
>>> result.co_consts[0]
3
由于 Code Object 对象保存了常量、变量、名称等一系列的上下文内容,所以可以直接对该对象进行反汇编操作:
>>> dis.dis(result)
1 0 SETUP_LOOP 30 (to 32)
2 LOAD_NAME 0 (range)
4 LOAD_CONST 0 (3)
...
现在,我们可以对 Python 字节码做一下小结了。Python 在编译某段源码时,并不会直接返回字节码,而是返回一个 Code Object 对象,字节码则保存在该对象的 co_code 字段中。由于字节码是一个二进制字节序列,无法直接进行阅读,所以需要通过”反汇编器”(dis 模块)将字节码转换成人类可读的助记符。助记符的形式和汇编语言非常类似,均由操作指令+操作数所组成。

3. 命名空间与作用域
Python 的命名空间与作用域经常被开发者所忽略,在未深入了解 Python 虚拟机之前,我个人也认为这些东西并不重要。但是,命名空间和变量作用域将会是 Python 虚拟机在执行过程中一个非常重要的一环。
命名空间实际上是名称到对象的一种映射,本质上就是一个键-值对,所以大部分的命名空间由 dict 实现。命名空间可以分为3类: 内置命名空间,全局命名空间与局部命名空间,在作用域存在嵌套的特殊情况下,可能还会有闭包命名空间。
3.1 内置命名空间(Build-in)
Python语言内置的名称,例如内置函数名(len, dis),内置异常(Exception)等。
>>> import builtins
>>> builtins.__dict__
3.2 全局命名空间(Global)
全局命名空间以模块进行划分,每一个模块中都包含了 dict 对象,其中保存了模块中的变量名、类名、函数名等等。在字节码中,全局变量的导入使用 LOAD_GLOBAL 。
3.3 局部命名空间(Local)
局部命名空间可以简单的认为就是函数的命名空间,例如函数参数,在函数中定义的局部变量。
下面是关于局部命名空间和全局命名空间的一个非常典型的例子:
number = 10
def foo():
number += 10
print(number)
if __name__ == "__main__":
foo()
UnboundLocalError: local variable 'number' referenced before assignment
在运行上述代码时将会抛出 UnboundLocalError 异常,这简直莫名其妙,在其它语言中,上述代码都能够正常运行,以 C 语言为例:
#include <stdio.h>
int number = 10;
int main() {
number += 10;
printf("%d\n", number); // 正常运行并打印结果: 20
}
但是在 Python 中却抛出了异常,这又是为什么? 官方在 Python FAQ 给出了相关解释,原文如下:
In Python, variables that are only referenced inside a function are implicitly global. If a variable is assigned a value anywhere within the function’s body, it’s assumed to be a local unless explicitly declared as global.
简单来说,当我们在函数中引用一个变量时,Python 将隐式地默认该变量为全局变量。但是,一旦变量在没有global关键字修饰的情况下进行了赋值操作,Python 会将其作为局部变量处理。
而语句 number += 10 进行了赋值动作,此时 number 为局部变量,该函数中又没有声明该局部变量,故而抛出异常。Python 这么做的目的就是为了防止开发者者在某些函数中修改了全局变量而又不自知,通过显式地添加 global 关键字来确保开发者知道自己在做什么。这正如 Python 之禅所述的,Explicit is better than implicit。
首先先来看下正常的局部变量在字节码中是如何处理的:
import dis
def foo():
number = 10
print(number)
if __name__ == "__main__":
print(dis.dis(foo))
0 LOAD_CONST 1 (10)
2 STORE_FAST 0 (number)
4 LOAD_GLOBAL 0 (print)
6 LOAD_FAST 0 (number)
STORE_FAST 将当前变量压入到函数运行栈中,而 LOAD_FAST 则从函数运行栈取出该变量。LOAD_FAST 之前必须存在 STORE_FAST,否则在运行时将会抛出异常。对于最初的例子而言,在未添加 global 关键字的情况下,语句 number += 10 将会直接执行 LOAD_FAST 指令,而此时当前变量并未压入至当前函数运行栈。
3.4 闭包命名空间(Enclosing)
当出现嵌套函数定义时,或者作用域嵌套时,Python 将会把内层作用域所依赖的所有外层命名存储在一个特殊的命名空间中,也就是闭包命名空间。
import logging as logger
def foo(func):
def wrapper(*args, **kwargs):
logger.info(f"Execute func: {func.__name__}")
func(*args, **kwargs)
return wrapper
在 foo 闭包函数中,参数 func 即属于闭包命名空间,内层函数 wrapper 在寻找变量时,若局部命名空间内无此变量,将会于闭包命名空间中进行查找。
如果在闭包函数中对外层函数的局部变量进行赋值会发生什么?
def foo():
number = 10
def bar():
number += 10
return bar
正如同在局部命名空间中提到的一样,当一个变量在函数中被赋值时,Python 默认将其作为全局变量,既不是局部变量,也不是这里提到的闭包空间变量。所以,当我们在实际运行 bar 方法时,同样会得到 UnboundLocalError 异常。在这里如果想要使用 foo 函数中的 number 变量的话,需要使用 nonlocal 关键字进行修饰,让 Python 去 bar 函数的最近外层,也就是 foo 寻找该变量的定义。
此外,闭包指函数,而不是类,所以在类的嵌套中,将不会存在闭包命名空间:
class Reader(object):
BUFFER_SIZE = 4096
class ReaderInternal(object):
def __init__(self):
self._buffer_size = BUFFER_SIZE * 2
# ...
if __name__ == "__main__":
Reader.ReaderInternal()
在执行 Reader.ReaderInternal() 语句时,将会抛出 NameError 的异常,表示 BUFFER_SIZE 未定义。
当语句需要查找变量 X 时,将会按照 Local -> Enclosing -> Global -> Builtin 的顺序进行查找,俗称 LEGB 规则。
4. Python虚拟机的执行
4.1 执行上下文——栈帧
在 x86-64 CPU 中包含了16个64位的通用目的寄存器,这些寄存器用于存储数据或者是指针。在这16个通用目的寄存器中,有两个较为特殊的寄存器: %rsp 与 %rbp。%rsp 为栈指针寄存器,表示运行时栈的结束位置,可以简单地理解为栈顶。%rbp 为栈帧指针,用于标识当前栈帧的起始位置。
在 x86 体系结构中,函数调用是通过栈和栈帧实现的。当一个函数被调用时,首先做的事情就是将调用者栈帧指针入栈,以保留调用关系。其次将为调用的函数创建栈帧,栈帧中包含了函数的参数、创建的局部变量等信息。
回到Python虚拟机中,虚拟机在进行函数调用时,运行方式和x86没什么区别,都是由栈和栈帧所实现的。而栈帧则是由 PyFrameObject 表示,于源码 cpython/Include/frameobject.h 中定义。
typedef struct _frame {
PyObject_VAR_HEAD /* Python固定长度对象头 */
struct _frame *f_back; /* 指向上一个栈帧的指针 */
PyCodeObject *f_code; /* Code Object代码对象,其中包含了字节码 */
PyObject *f_builtins; /* 内建命名空间字典(PyDictObject) */
PyObject *f_globals; /* 全局命名空间字典(PyDictObject) */
PyObject *f_locals; /* 局部命名空间表(通常是数组) */
int f_lasti; /* 上一条指令编号 */
...
} PyFrameObject;
可以看到,在一个栈帧中包含了Code Object代码对象,三个命名空间表,上一个栈帧指针等信息。可以说,PyFrameObject 对象包含了Python虚拟机执行所需的全部上下文。在 Python 源码层面,可以通过 sys 模块中的 _getframe 方法来获取当前函数运行时的栈帧,方法将返回 FrameType 类型,其实就是 PyFrameObject 简化后的 Python 结构。
下面通过一段简单的代码来具体看下 Python 运行时的栈帧结构:
import sys
def first():
middle()
def middle():
finish()
def finish():
print_frame()
def print_frame():
current_frame = sys._getframe()
while current_frame:
print(f"func name: {current_frame.f_code.co_name}")
print("*" * 20)
current_frame = current_frame.f_back
if __name__ == "__main__":
first()
func name: print_frame
****************************************
func name: finish
****************************************
func name: middle
****************************************
func name: first
****************************************
func name: <module>
****************************************
在 Python 开始执行该程序时,首先创建一个用于执行模块代码对象的栈帧对象,也就是 module 。随着一个一个的函数调用,不同的栈帧对象将会被创建,并且压入至运行栈中,而连接这些栈帧对象的纽带就是 f_back 指针。当栈顶的函数执行完毕开始返回时,将沿着 f_back 指针方向一直到当前调用链的起始位置。
结合前面提到的字节码和命名空间,我们可以用一张简图来描述。
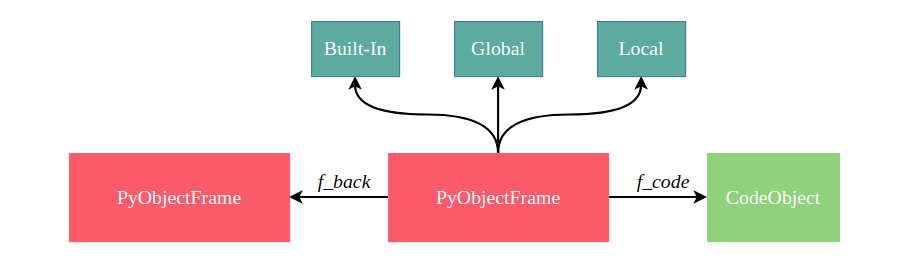
4.2 指令的执行
指令执行的源码均位于 cpython/Python/ceval.c 中,入口函数有两个,一个是 PyEval_EvalCode ,另一个则是 PyEval_EvalCodeEx ,最终的实际调用函数为 _PyEval_EvalCodeWithName,所以我们只需要关注该函数即可。
_PyEval_EvalCodeWithName 函数的主要作用为进行函数调用的例常检查,例如校验函数参数的个数、类型,校验关键字参数等。除此之外,该函数将会初始化栈帧对象并将其交给 PyEval_EvalFrame 函数进行处理,最终由 _PyEval_EvalFrameDefault 函数真正的运行指令。
_PyEval_EvalFrameDefault 函数定义超过了3K行,绝大部分的逻辑其实都是 switch-case : 根据指令类型执行相应的逻辑。
for (;;) {
switch (opcode) {
case TARGET(LOAD_CONST): { /* 加载常量 */
...
}
case TARGET(ROT_TWO): { /* 交换两个变量 */
...
}
case TARGET(FORMAT_VALUE):{ /* 格式化字符串 */
...
}
可以看到 TARGET() 调用中的参数其实就是 dis 方法返回的助记符,当我们在分析助记符的具体实现逻辑时,可以在该文件中找到对应的 C 实现方法。
4.3 GIL 与字节码的执行
对于 Python 中的容器,例如 dict,并没有实现像 Java 中的 ConcurrentHashMap,或者是 Golang 中的 sync.Map,这是因为 Python 中的容器(list, dict)本身就是并发安全的,但是在这些容器的源码中并没有发现定义 mutex,也就是说,Python 容器的并发安全并不是通过互斥锁实现的。
实际上,Python 容器的并发安全是通过 GIL 实现的,也就是被广大 Pythoner 口诛笔伐的全局解释器锁。某一个线程想要运行必须要首先获取全局锁,如此一来,在同一时刻只能有一个线程运行,无法充分利用多核的硬件资源。
Python 的线程调度非常类似于 CPU 的时间片实现,只不过并不是以时间为判断标准,而是以执行字节码的数量作为判断标准。当某一个线程执行了足够多的字节码条数时,当前线程将释放全局锁,唤醒其它线程进行执行。
所以,得益于 GIL 的存在,Python 容器在进行诸如扩容、缩容操作时,完全不必担心并发问题,因为一条字节码的执行一定是原子性的。