在MySQL中, 锁机制是并发条件下保护数据一致性与稳定性的一个非常重要的机制, 并且事务的实现也依赖于于锁机制。 其锁定的数据不单包括数据行记录, 同时也包括缓冲池中的LRU列表数据、日志数据等。 悲观锁(FOR UPDATE)则是日常开发中使用最多的一种锁, 但是, 由于事务隔离级别的多样性导致了悲观锁在使用时常常会有不同的表现, 死锁在程序员稍不注意时就会发生。
1. 悲观锁概述
在通用的程序设计语言中, 锁通常是基于某一个对象, 或者是一组对象而言。 在Python、Java和Golang中, 分别提供了threading.Lock、synchronized以及sync.Mutex互斥所机制。 而数据库要更为特殊一些, 其原因就在于我们所管理的不是一个个的对象, 而是一行行的数据。
InnoDB存储引擎支持的最小锁粒度为行锁, 可以通过在事务中执行SELECT .. FOR UPDATE为某一行或者是多行数据添加互斥锁。 锁的生命周期完全由InnoDB管理, 当事务成功提交或者是失败回滚时, 互斥锁则自动释放。
需要注意的一点是, 互斥锁必须在事务中执行才会生效。 当autocommit为ON时, 需要显示的使用BEGIN开启事务, 而后对数据添加互斥锁。
在程序设计语言中, 锁的目的是串行化修改、删除操作, InnoDB中的互斥锁有着同样的目的。 但是, 由于事务隔离级别的分类, 使得互斥锁的行为变得复杂许多。 其中最让人感到迷惑的就是为了解决幻读问题所添加的GAP Lock。
2. 事务隔离级别概述
不同的事务隔离级别, 悲观锁会产生不同的行为。 所以, 理解事务隔离级别是理解悲观锁的第一步。
InnoDB事务隔离级别从低到高依次为未提交读(READ UNCOMMITED), 提交读(READ COMMITED), 可重复读(READ REPEATABLE)以及串行化(SERIALIZABLE)。
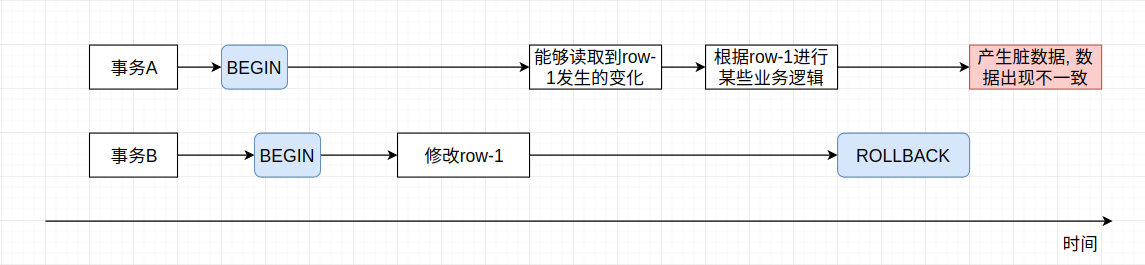
未提交读指的是事务B可以读取到事务A未提交的数据, 此时若事务A回滚, 那么事务B读到的就是错误数据, 也称为脏数据。 该读取行为有时也会被称为脏读, 因为未提交读会导致脏读的问题, 从而导致数据混乱, 所以该事务隔离级别基本不会被使用。
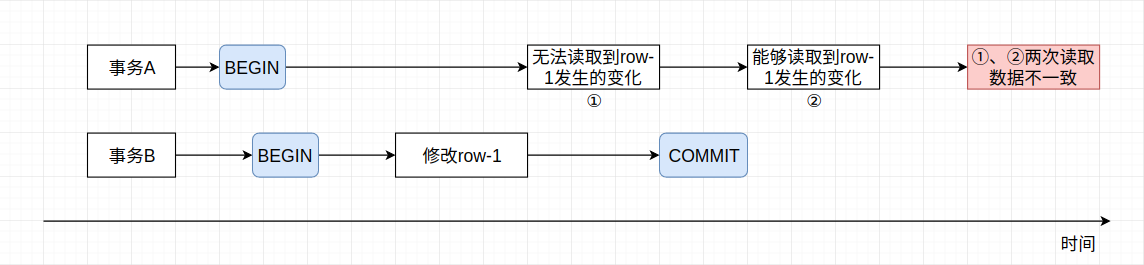
提交读是指在执行事务B时, 可以读取到事务A提交到的数据, 未提交的数据不可读取。 提交读解决了脏读的问题, 读取到的数据一定是已经持久化至磁盘的数据, 但是会出现同一条SQL语句在执行时出现不一致的情况。 例如事务A、B先后开始执行, 事务A首先读取row-1的内容, 而此时事务B对row-1的内容修改并提交, 此时事务A再次读取row-1数据, 发现其已经发生改变, 而该变化并不是事务A自身进行的。 这种情况又称为不可重复读。
可重复读, 顾名思义, 解决了提交读的不可重复读问题, 使得事务在读取同一行数据时, 结果并不会因为其它事务的执行而发生改变, 数据发生的修改行为在整个事务内是可以自恰的。 但是并没有解决幻读的问题, 幻读是指其余事务在某一个区间内插入数据, 而非修改数据, 此时事务也会读取到这部分插入的数据。 InnoDB借助MVCC(多版本并发控制)以及锁机制来解决幻读问题。
MVCC即在数据中添加版本号, 数据插入时会有初始版本号, 在修改、删除时更新版本号。

串行化指事务串行化执行, 自然就不会有出现上述出现的脏读、不可重复读以及幻读了。 一个很重要的事实是, 串行化的事务隔离级别执行效率并不会比可重复读事务隔离级别差很多。 同样的, 提交读执行效率也不会比可重复读执行效率高多少, 所以在优化数据库时, 事务隔离级别不应该是效率优化目标, 而是业务优化目标。
3. MySQL中的锁
使用FOR UPDATE对某一行或者是多行数据添加的锁, 其实是由MySQL更细粒度的锁组合而成的, 不同的事务隔离级别有不同的组合方式。
在InnoDB存储引擎中, 存在3种行锁的算法, 其分别为:
- Record Lock: 单个行记录上的锁,聚集索引及辅助索引均会添加锁。
- Gap Lock: 间隙锁, 锁定一个范围, 但不包含行记录本身。
- Next-Key Lock: Record Lock + Gap Lock,锁定行记录本身并且锁定一个范围。
下面用一个实际的例子来解释Record Lock以及Gap Lock。 首先表结构定义如下:
CREATE TABLE lock_test (
id int(11) NOT NULL AUTO_INCREMENT,
a varchar(6) NOT NULL,
PRIMARY KEY (id),
KEY (a)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- 插入部分测试数据
insert into lock_test (a) values ("1");
insert into lock_test (a) values ("3");
insert into lock_test (a) values ("5");
insert into lock_test (a) values ("8");
接着执行下面的语句:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM lock_test WHERE a = “5” FOR UPDATE; |
|
| 3 | BEGIN; | |
| 4 | INSERT INTO lock_test (a) VALUES (“4”); 阻塞,等待会话A事务的提交 |
|
| 5 | COMMIT; | Query OK, 1 row affected (6.87 sec) |
尽管列a添加了辅助索引, 但是在对该列使用FOR UPDATE添加悲观锁时, 仍然会出现其它列被锁定的现象。 这是因为a = "5"该行数据不仅被添加了Record Lock, 并且也添加了Gap Lock, 其目的就是为了解决幻读问题, 前提是当前事务隔离级别为REPEATABLE READ。
在列a的辅助索引中, 值”5”之前的值为”3”, 故存在(3, 5)这个间隙, 所以在插入值”4”时, InnoDB为了杜绝幻读现象的发生, 使得只有在会话A事务提交时才允许插入操作的进行。 另外一点需要注意的是, 当查询的索引具有唯一属性时, InnoDB存储引擎会对Next-Key Lock进行优化, 将其降级为Record Lock, 即仅锁住索引本身, 而不锁定一个范围。
For a unique index with a unique search condition, InnoDB locks only the index record found, not the gap before it.
4. 锁与事务之间的关联
前面提到了Gap Lock的存在主要是为了解决幻读问题的发生, 而在READ COMMITTED事务隔离级别中, 只解决了脏读问题, 所以说, 在该事务隔离级别下, FOR UPDATE仅会添加Record Lock, 并不会添加Gap Lock。
For locking reads (SELECT with FOR UPDATE or FOR SHARE), UPDATE statements, and DELETE statements, InnoDB locks only index records, not the gaps before them.
Because gap locking is disabled, phantom problems may occur, as other sessions can insert new rows into the gaps
此外, 如果用户通过索引查询一个值, 并在其之上添加排它锁, 当查询的值不存在时, READ COMMITTED与REPEATABLE READ两个事务隔离级别所产生的行为同样存在差异, 一个最直观的差异就是REPEATABLE READ在并发条件下会产生死锁, 而READ COMMITTED则不会。
READ COMMITTED事务隔离级别:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM lock_test WHERE a = “100” FOR UPDATE; |
|
| 3 | BEGIN; | |
| 4 | SELECT * FROM lock_test WHERE a = “100” FOR UPDATE; 不会被阻塞 |
|
| 5 | INSERT INTO lock_test (a) VALUES (“100”); 不会被阻塞 |
|
| 6 | INSERT INTO lock_test (a) VALUES (“100”); 不会被阻塞 |
|
| 7 | COMMIT; | |
| 8 | COMMIT; |
所以说, 当事务隔离级别为READ COMMITTED时, 无法使用Next-Key Lock来帮助我们实现类似于update_or_create或者是get_or_create等方法, 因为在并发条件下会造成重复数据创建, 除非表中存在唯一索引。 这也是Django框架官网中所提到的Multiply records问题。 感兴趣的小伙伴可访问官网获取更多详细内容:
https://docs.djangoproject.com/en/2.2/ref/models/querysets/#get-or-create
REPEATABLE READ事务隔离级别:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM lock_test WHERE a = “200” FOR UPDATE; |
|
| 3 | BEGIN; | |
| 4 | SELECT * FROM lock_test WHERE a = “200” FOR UPDATE; 不会被阻塞 |
|
| 5 | INSERT INTO lock_test (a) VALUES (“200”); 阻塞, 等待事务B的结束 |
|
| 6 | INSERT INTO lock_test (a) VALUES (“200”); ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction,死锁发生 |
当在REPEATABLE READ事务隔离级别级别下实现get_or_create方法时,会产生死锁问题, 原因就在于锁定的记录并不存在, 多个事务可同时对其添加悲观锁, 但是插入语句的执行位置是不确定的, 所以就会有死锁问题的出现。解决此类问题的一个方法就是使用指数退避方式的重试。
5. 死锁
通常来讲, 如果我们的SQL执行计划较为简单, 几乎所有的执行均为单条语句执行时, 死锁基本与我们无关。 但是当执行计划稍加复杂, 事务执行的语句较多时, 就会出现死锁问题。 一个最经典的死锁场景即为AB-BA死锁。
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM lock_test WHERE a = “200” FOR UPDATE; |
|
| 3 | BEGIN; | |
| 4 | SELECT * FROM lock_test WHERE a = “400” FOR UPDATE; |
|
| 5 | SELECT * FROM lock_test WHERE a = “400” FOR UPDATE 阻塞, 等待事务B的结束 |
|
| 6 | SELECT * FROM lock_test WHERE a = “200” FOR UPDATE; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction,死锁发生 |
当MySQL检测到死锁时, 会根据其事务权重选择性的回滚其中一个事务。 但是, 权重的判定完全由MySQL决定, 业务系统无法人为的干预, 如果某一个事务在业务系统中非常重要, 但是MySQL却回滚了该事务, 而业务系统仅捕捉了该异常并向外扩散的话, 并不是我们期望的结果。 所以, 在绝大多数场景下, 指数退避的重试策略要更好一些。 或者对于关键性的业务逻辑, 使用Redis等消息队列进行串行化操作。
另外一个死锁场景则是上一小节中我们所见到的并发执行if not exist then create模式所带来的死锁问题, 该模式在业务场景下其实非常常见。
Reference
- https://dev.mysql.com/doc/refman/8.0/en/innodb-transaction-isolation-levels.html
- https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
- https://dev.mysql.com/doc/refman/8.0/en/innodb-deadlocks.html