在上一篇文章中, 通过解析InnoDB存储引擎的.ibd数据存储文件得到了数据与索引的真实组织方式: 数据通过聚集索引在逻辑上连续存放, 二级索引保存数据主键ID(Row ID), 多棵B+Tree组合起来提供高效的索引数据查询。 除辅助索引(二级索引)外, 联合索引与覆盖索引在日常中也会经常用到。
1. 联合索引
CREATE TABLE union_test (
id int(11) NOT NULL AUTO_INCREMENT,
user_id varchar(4) NOT NULL,
order_id varchar(5) NOT NULL,
PRIMARY KEY (id),
KEY ix_union_order_id_user_id (user_id, order_id)
) ENGINE=InnoDB DEFAULT CHARSET=LATIN1;
INSERT INTO union_test (user_id, order_id) VALUES ("0000", "A0000");
INSERT INTO union_test (user_id, order_id) VALUES ("0000", "A0001");
INSERT INTO union_test (user_id, order_id) VALUES ("0001", "A0003");
...
在创建表结构以及插入部分测试数据之后, 我们依然使用hexdump -C来对.ibd文件进行分析, 从最基本的数据存储结构中更能够发现联合索引的存储特点。
00010070 73 75 70 72 65 6d 75 6d 03 04 00 00 10 00 36 30 |supremum......60|
00010080 30 35 38 41 31 34 80 00 00 01 03 04 07 00 18 05 |058A14..........|
00010090 e2 30 30 33 36 41 32 30 80 00 00 02 03 04 08 00 |.0036A20........|
000100a0 20 00 fb 30 30 34 33 41 31 33 80 00 00 03 03 04 | ..0043A13......|
000100b0 00 00 28 01 67 30 30 35 39 41 32 31 80 00 00 04 |..(.g0059A21....|
000100c0 03 04 08 00 30 02 65 30 30 34 39 41 38 39 80 00 |....0.e0049A89..|
000100d0 00 05 03 04 00 00 38 01 1f 30 30 35 31 41 35 34 |......8..0051A54|
000100e0 80 00 00 06 02 04 06 00 40 05 76 30 30 32 33 41 |........@.v0023A|
000100f0 36 80 00 00 07 03 04 00 00 48 02 0c 30 30 30 31 |6........H..0001|
00010100 41 35 30 80 00 00 08 03 04 00 00 50 06 19 30 30 |A50........P..00|
00010110 31 35 41 39 31 80 00 00 09 03 04 00 00 58 ff 83 |15A91........X..|
00010120 30 30 34 32 41 37 32 80 00 00 0a 03 04 00 00 60 |0042A72........`|
00010130 01 56 30 30 33 38 41 39 35 80 00 00 0b 03 04 00 |.V0038A95.......|
00010140 00 68 03 4f 30 30 32 39 41 39 37 80 00 00 0c 03 |.h.O0029A97.....|
00010150 04 05 00 70 05 41 30 30 35 37 41 31 31 80 00 00 |...p.A0057A11...|
00010160 0d 03 04 00 00 78 02 c0 30 30 31 39 41 35 32 80 |.....x..0019A52.|
直接截取部分的联合索引内容进行分析, 索引数据从00010078开始:
03 04 /* 倒序索引长度列表 */
00 00 10 00 36
30 30 35 38 /* 列1索引数据 */
41 31 34 /* 列2索引数据 */
80 00 00 01 /* 主键id */
可以看到, 联合索引的物理存储方式与单一索引的最大区别就是索引数据不是分开存储的。 所以, 联合索引要比两个或多个单独的索引占用更少的磁盘空间。
事实上, 联合索引与单列索引在组织形式上没什么区别, 都是一棵B+Tree。 只不过联合索引的键值数量不是1, 而是大于等于2。
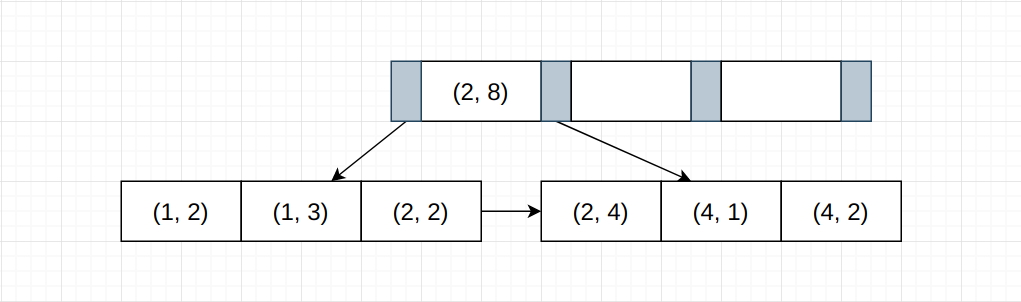
如上图所示, 联合索引的第1列数据将严格按照B+Tree的字典序进行排序, 第2列数据则在第一列数据有序的基础上进行排序。 可以认为, 联合索引的B+Tree结构就是对一个多维数组进行排序, 以Python为例:
# 假设有如下数据
unsorted_list = [(4, 2), (4, 1), (2, 5), (2, 4), (1, 2), (1, 3)]
res = sorted(unsorted_list)
# Out: [(1, 2), (1, 3), (2, 4), (2, 5), (4, 1), (4, 2)]
假设现在有两列数据a, b组合成为了联合索引, 那么当a列相同时, b列数据一定是有序存放的, 也就是说当执行:
SELECT * FROM table WHERE a = XX AND b = XX;
其效率要高于a, b两个单独的索引列查询, 原因就在于其索引数据保存在同一棵B+Tree中, 使用更少的逻辑I/O就能将数据取出。
在单独查询列a时, 依然可以使用联合索引进行查询, 但是在单独查询b列时, 则不可以使用联合索引。 因为b列数据并不是有序存放的。
如上例所示, b列的数据为[2, 3, 2, 4, 1, 2], 完全无序, 故使用:
SELECT * FROM table WHERE b = XX;
进行查询时将无法使用联合索引。 联合索引除了能加速查询以外, 还有另外一个好处, 就是加速ORDER BY的查询。
这也很好理解, 因为在建立了联合索引以后, 第2列数据, 甚至是第n列数据, 将会有序的组成B+Tree, 如此一来就省去了排序的的时间。
假设现在有4列数据a, b, c, d组成的联合索引(a, b, c, d), 那么B+Tree的结构为a有序排列, b在a相同的情况下有序排列, c在b相同的情况下有序排列, d在c相同的情况下有序排列。 在查询时, 只要查询条件包含a字段, 均可以使用索引进行查询。
2. 覆盖索引(Cover Index)
现在我们已经知道了InnoDB的物理存储方式是一个聚集索引+多个辅助索引组成, 辅助索引包含单列索引以及上面提到的联合索引。 在使用索引进行数据查询时, 首先在辅助索引树中找到该条数据对应的主键id(Row ID), 而后根据主键id在聚集索引树中进行查询, 粗略的认为就是2次逻辑I/O。
覆盖索引的本质就是不使用聚集索引, 只使用辅助索引就能够将所需要的数据查询出来, 最典型的例子就是count(*)。
当某张表内存在二级索引时, count(*)将直接统计二级索引的数量并返回。 由于二级索引的B+Tree要比聚集索引更加的矮胖, 每页能够容纳更多的索引数据行, 所以其效率要高于扫描聚集索引。
CREATE TABLE count_test (
id int(11) NOT NULL AUTO_INCREMENT,
user_id varchar(8) NOT NULL,
PRIMARY KEY (id),
KEY ix_user_id (user_id)
) ENGINE=InnoDB DEFAULT CHARSET=LATIN1;

如果表内有多个二级索引, 则count(*)将会选择长度最短的二级索引。 索引长度越短, 每页就能够容纳更多的数据, 就会有更少的逻辑I/O, 因此效率也就越高。
ALTER TABLE count_test ADD order_id varchar(4) NOT NULL;
ALTER TABLE count_test ADD KEY (order_id);

覆盖索引严格意义上来讲是MySQL的查询优化器所做的优化, 并不是物理上存在的索引。 但是, 借助于覆盖索引的特点, 我们可以有目的的对某些查询进行优化。
3. 小结
联合索引是优化多字段查询以及需要对某个字段进行排序的一种手段, 而覆盖索引则是MySQL查询优化器的一种优化策略, 并不能称为真正意义上的索引。